稍微了解一点类 UNIX 系统的进程管理的都知道,当一个进程的父进程死亡之后,它就变成了孤儿进程,会由进程号 1 的 init 进程收养,并且在它死亡时由 init 来收尸。但是,自从使用 systemd 来管理用户级服务进程之后,我发现 systemd --user 管理的进程总是在它之下,即使进程已经 fork 了好几次。systemd 是怎么做到的呢?
对一个软件的实现有不懂的想了解当然是读它的源码了。这种东西可没有另外的文档,因为源码本身即文档。当然之前我也 Google 过,没有得到结果。在又一个全新的源码树里寻寻觅觅一两天之后,终于找到了这个:
if (arg_running_as == SYSTEMD_USER) {
/* Become reaper of our children */
if (prctl(PR_SET_CHILD_SUBREAPER, 1) < 0) {
log_warning("Failed to make us a subreaper: %m");
if (errno == EINVAL)
log_info("Perhaps the kernel version is too old (< 3.4?)");
}
}
原来是通过prctl系统调用实现的。于是去翻 prctl 的 man 手册,得知PR_SET_CHILD_SUBREAPER是 Linux 3.4 加入的新特性。把它设置为非零值,当前进程就会变成 subreaper,会像 1 号进程那样收养孤儿进程了。
当然用 C 写不好玩,于是先用 python-cffi 玩了会儿,最后还是写了个 Python 模块,也是抓住机会练习一下 C 啦。有个 python-prctl 模块,但是它没有包含这个调用。
#include<sys/prctl.h>
#include<Python.h>
static PyObject* subreap(PyObject *self, PyObject *args){
PyObject* pyreaping;
int reaping;
int result;
if (!PyArg_ParseTuple(args, "O!", &PyBool_Type, &pyreaping))
return NULL;
reaping = pyreaping == Py_True;
Py_BEGIN_ALLOW_THREADS
result = prctl(PR_SET_CHILD_SUBREAPER, reaping);
Py_END_ALLOW_THREADS
if(result != 0){
return PyErr_SetFromErrno(PyExc_OSError);
}else{
Py_RETURN_NONE;
}
}
static PyMethodDef mysysutil_methods[] = {
{"subreap", subreap, METH_VARARGS},
{NULL, NULL} /* Sentinel */
};
static PyModuleDef mysysutil = {
PyModuleDef_HEAD_INIT,
"mysysutil",
"My system utils",
-1,
mysysutil_methods,
NULL, NULL, NULL, NULL
};
PyMODINIT_FUNC PyInit_mysysutil(void){
PyObject* m;
m = PyModule_Create(&mysysutil);
if(m == NULL)
return NULL;
return m;
}
编译之后,
>>> import mysysutil
>>> mysysutil.subreap(True)
然后开子进程,不管它 fork 多少次,都依然会在这个 Python 进程之下啦。
但是,这样子不太好玩呢。如果我登陆之后所有启动的子进程都在一个进程之下不是更有意思么?于是我打上了 Awesome 的主意,因为它支持运行任意的 Lua 代码嘛。于是我又给这个 prctl 调用弄了个 Lua 绑定。最终的版本如下:
#include<lua.h>
#include<lualib.h>
#include<lauxlib.h>
#include<sys/prctl.h>
#include<sys/wait.h>
#include<errno.h>
#include<string.h>
#include<signal.h>
static int l_setsubreap(lua_State * L){
int reap;
if(lua_isboolean(L, 1)){
reap = lua_toboolean(L, 1);
}else{
return luaL_argerror(L, 1, "not a boolean");
}
if(prctl(PR_SET_CHILD_SUBREAPER, reap) != 0){
return luaL_error(L, "prctl failed: %s", strerror(errno));
}
return 0;
}
static int l_ignore_SIGCHLD(lua_State * L){
signal(SIGCHLD, SIG_IGN);
return 0;
}
static int l_reap(lua_State * L){
int pid, st;
pid = waitpid(-1, &st, WNOHANG);
lua_pushinteger(L, st);
lua_pushinteger(L, pid);
return 2;
}
static const struct luaL_Reg l_lib[] = {
{"setsubreap", l_setsubreap},
{"reap", l_reap},
{"ignore_SIGCHLD", l_ignore_SIGCHLD},
{NULL, NULL}
};
int luaopen_clua(lua_State * L){
lua_newtable(L);
luaL_setfuncs(L, l_lib, 0);
return 1;
}
除了调用 prctl 外,还增加了显式忽略 SIGCHLD 信号,以及非阻塞地调用 waitpid 收割单个僵尸进程的函数,因为 Awesome 本身没处理子进程退出,我一不小心弄出了好几个僵尸进程……对了,那个 waitpid 要注意给弄成非阻塞的,不然一不小心就会出问题。
用的时候就是这样子,可以写到rc.lua里,也可以在 awesome-client 里调用:
package.cpath = package.cpath .. ';/home/lilydjwg/scripts/lua/cmod/?.so'
clua = require('clua')
clua.setsubreap(true)
clua.ignore_SIGCHLD()
最终,我的进程树成了这样子:
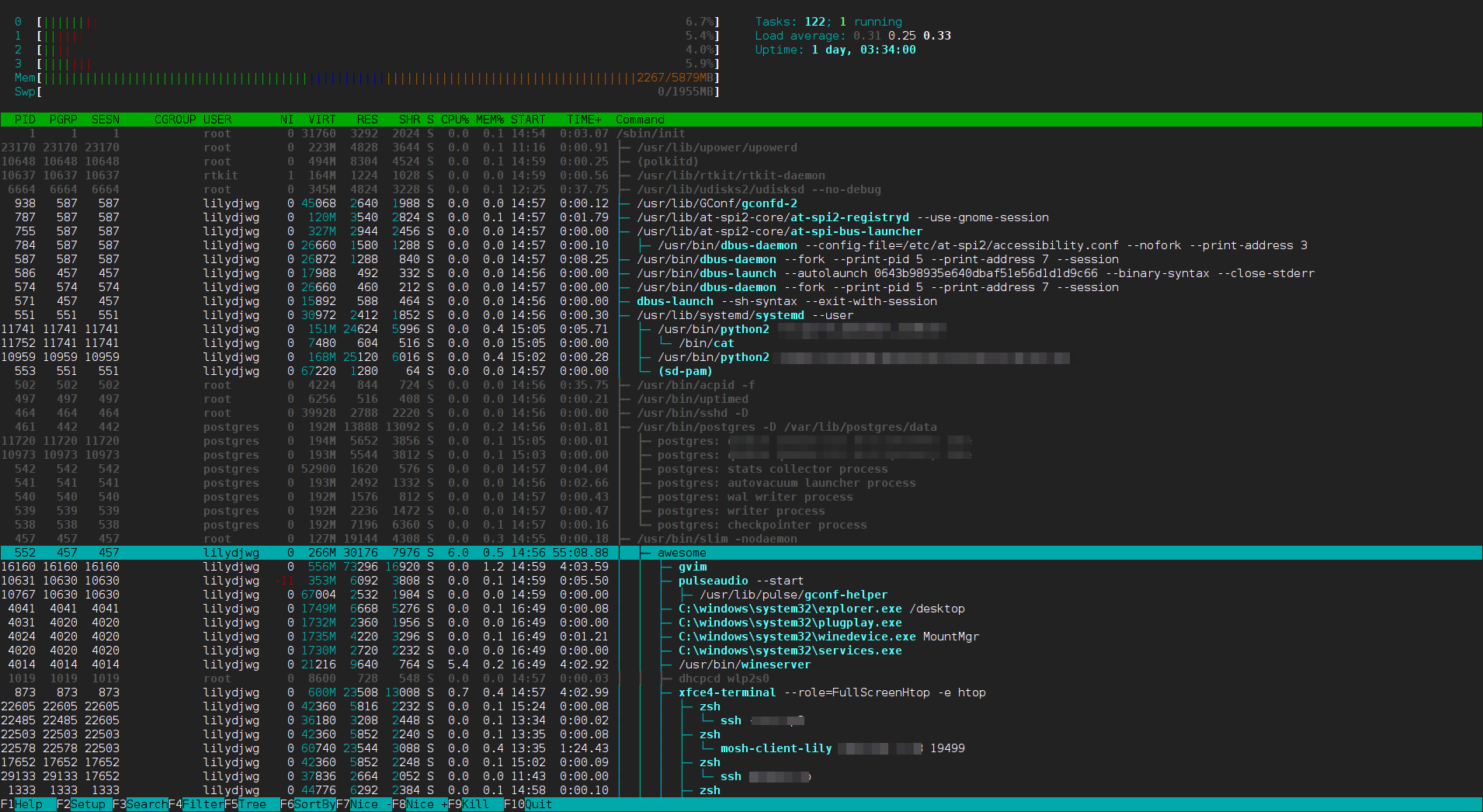
可以看到,由 Awesome 启动的进程已经全部待在 Awesome 进程树之下了。systemd --user 是由 PAM 启动的,所以不在 Awesome 树下。但是,那些 dbus 的东西和 gconfd-2、at-spi 之类的是怎么回事呀……

