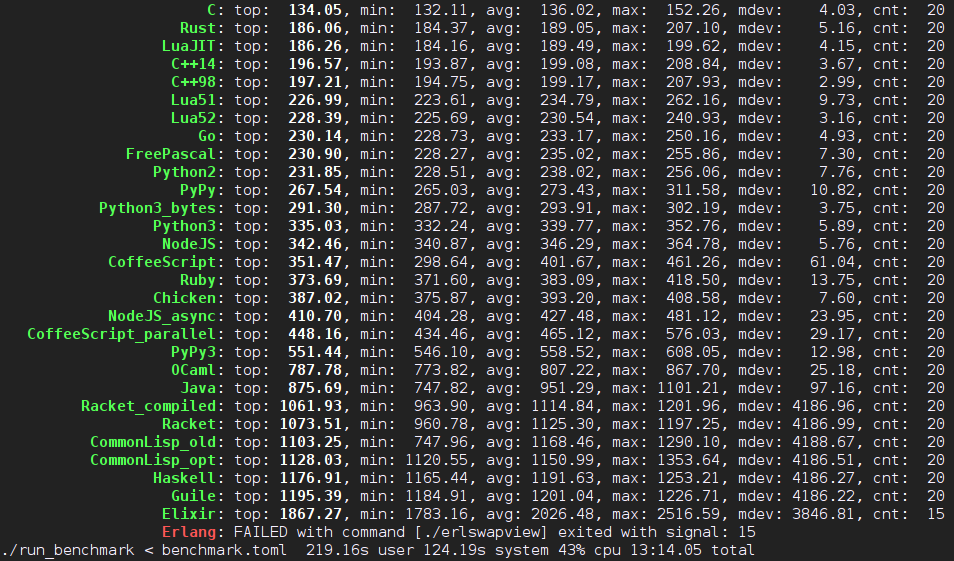
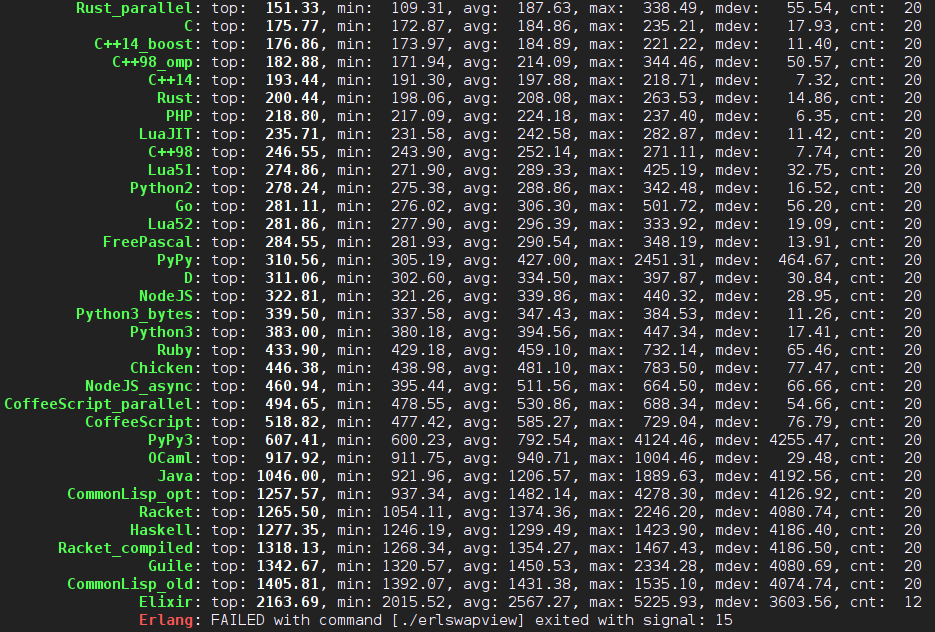
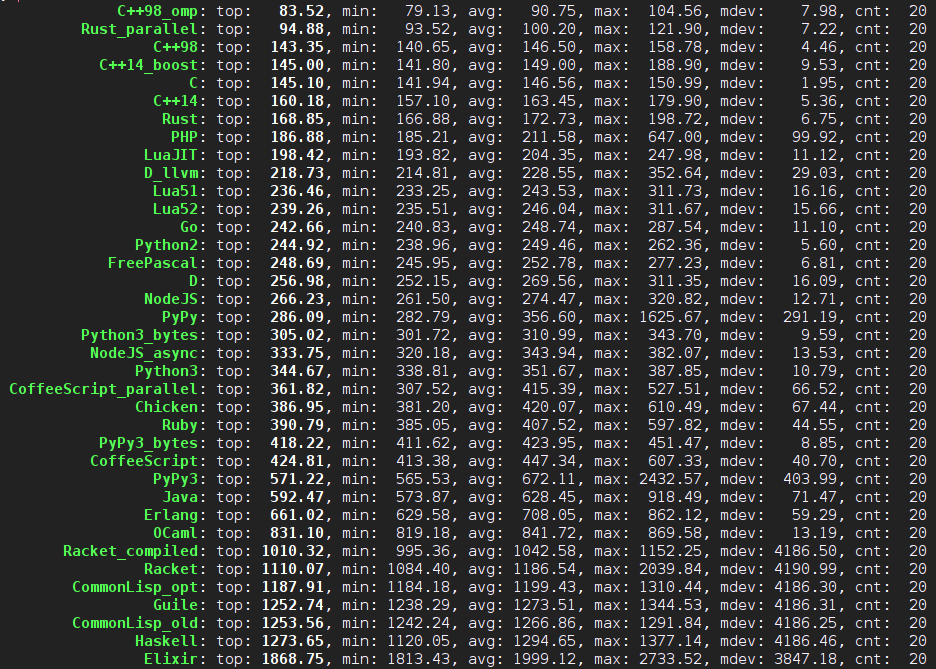
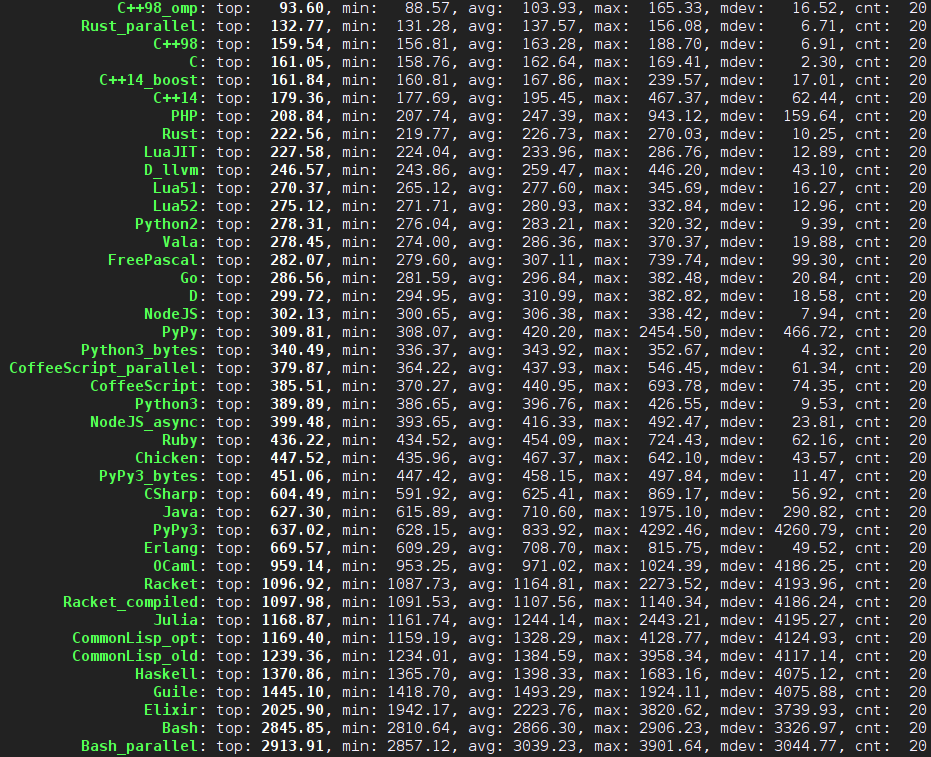
既然来学 Haskell 了,Parsec 不应该错过。lrc 文件的格式大家应该都清楚。虽然说它用正则表达式解析很容易也很可靠,但是,我这不是练习么!
数据类型的定义
首先,我们想想歌词文件解析出来有些什么。主要数据当然是一条条带时间的歌词!除此之外,还会可选地有歌名啦歌手啦之类的东西。
先来定义一条歌词,也就是一个最高精确到百分之一秒的时间,和一个字符串。也就是:
data LrcLine = LrcLine {
time :: Int,
line :: String
} deriving (Eq, Show, Ord)
我们需要实现Ord类型类以便比较,因为 lrc 文件的歌词有一种紧凑的格式,在相同的歌词前有多个时间。这时,歌词就不是排好序的了。GHC 会自动推断出比较函数,也就是逐个域地进行比较。也可以手动定义其为Ord的实例:
-- import Data.Function (on)
instance Ord LrcLine where
compare = compare `on` time
然后是整个歌词文件的信息:
data Lrc = Lrc {
title :: Maybe String,
artist :: Maybe String,
album :: Maybe String,
by :: Maybe String,
metadata :: [(String, String)],
lyrics :: [LrcLine]
}
因为可能会有未知的元信息,所以我们定义了一个metadata域来存储之。其类型为[(String, String)],以便使用lookup函数进行查询。
自顶向下设计解析器:顶层解析器
据RWH的说明,似乎一般都不写解析器的类型签名。但既然是初学嘛,我还是写上好了——
lrcParser :: GenParser Char st Lrc
什么意思我还不太懂,不过最后那个Lrc很显然就是解析结果的类型啦。
我们的解析器先从歌词源文件中读取若干行的元信息,接下来读取所有的歌词数据,最后构造个 Lrc类型的数据。
lrcParser = do
metadata <- many $ try lrcMeta
ly <- concat <$> many lrcLine
return Lrc {
title = lookup "ti" metadata,
artist = lookup "ar" metadata,
album = lookup "al" metadata,
by = lookup "by" metadata,
metadata = metadata,
lyrics = sort ly
}
many和try都是 Parsec 里的函数。many接受一个类型为解析器的参数,在求值时它一直调用这个解析器,直到它不消耗输入为止。如果这个解析器消耗了输入却又没能成功,那么整个many解析器也就失败了。而try在消耗了任意数量的输入但没有最终成功时会把已消耗的输入退回去,结果是没有消耗输入。开个 GHCi 会话演示下:
>>> ghci
GHCi, version 7.0.3: http://www.haskell.org/ghc/ :? for help
Loading package ghc-prim ... linking ... done.
Loading package integer-gmp ... linking ... done.
Loading package base ... linking ... done.
Loading package ffi-1.0 ... linking ... done.
ghci> import Text.ParserCombinators.Parsec
ghci> let p = string "ab" :: GenParser Char st String
Loading package transformers-0.2.2.0 ... linking ... done.
Loading package mtl-2.0.1.0 ... linking ... done.
Loading package bytestring-0.9.1.10 ... linking ... done.
Loading package array-0.3.0.2 ... linking ... done.
Loading package containers-0.4.0.0 ... linking ... done.
Loading package deepseq-1.1.0.2 ... linking ... done.
Loading package text-0.11.0.5 ... linking ... done.
Loading package parsec-3.1.2 ... linking ... done.
ghci> parse p "<string>" "abc"
Right "ab"
ghci> parse p "<string>" "ac"
Left "<string>" (line 1, column 1):
unexpected "c"
expecting "ab"
ghci> parse p "<string>" "d"
Left "<string>" (line 1, column 1):
unexpected "d"
expecting "ab"
ghci> parse p "<string>" ""
Left "<string>" (line 1, column 1):
unexpected end of input
expecting "ab"
ghci> parse (many p) "<string>" "ababc"
Right ["ab","ab"]
ghci> parse (many p) "<string>" "ababa"
Left "<string>" (line 1, column 5):
unexpected end of input
expecting "ab"
ghci> parse (many $ try p) "<string>" "ababa"
Right ["ab","ab"]
所以,many $ try lrcMeta就是不断尝试解析歌词元信息,直到解析失败时停止。
接下来是对歌词数据的解析。因为一行可能有多个时间,我们把它存储成多条LrcLine,所以需要使用concat来连接下每次调用lrcLine返回的结果列表。
自顶向下设计解析器:余下的部分
lrcMeta很简单,一行文本,由中括号括起来,其中的键和值用冒号隔开:
lrcMeta :: GenParser Char st (String, String)
lrcMeta = do
char '['
key <- many $ noneOf ":"
char ':'
val <- many $ noneOf "]"
char ']'
eol
return (key, val)
lrcLine差不多,不过涉及到时间的解析:
lrcLine :: GenParser Char st [LrcLine]
lrcLine = do
times <- many1 lrcTime
line <- many $ noneOf "\r\n"
optional eol
return $ map (\t -> LrcLine {
time = t,
line = line
}) times
嗯?没看到对时间的解析?哦,它在这里:
lrcTime :: GenParser Char st Int
lrcTime = do
char '['
minutes <- readInt
char ':'
second <- readInt
centisec <- option 0 $ char '.' >> readInt
char ']'
return $ 60 * 100 * minutes + 100 * second + centisec
where readInt = read <$> many digit
好了,你可以编译下试试了。RWH说过了,Compile early, compile often
。这样在你不小心出错时,强大的编译器能够及时提示你。
哦,下边是 import 列表:
import Data.Char (isDigit)
import Data.Functor ((<$>))
import Data.List (sort)
import Data.Maybe (isJust, fromJust)
import Text.ParserCombinators.Parsec
你试过了吗?发生了什么?
是的,我还有个「抄袭」RWH的换行符解析器没列出来。链接在文末给出了,大家自己去找吧 ;-)
什么?你没找到?好吧,那你加上这个,也可以编译的了。其实类型的语句早该写的。
eol :: GenParser Char st String
eol = undefined
这样就定义了eol函数,它被定义为一个匹配任意类型的「未定义」值。
最后加点工具函数
一个给把 offset 加到歌词数据里的,另一个则是给歌词在时间轴上偏移一定时间的。
lrcAddOffset :: Lrc -> Lrc
lrcAddOffset l = l { lyrics = ly', metadata = meta' }
where ly = lyrics l
meta = metadata l
offset = lookup "offset" meta >>= parseInt
ly' = case offset of
Just t -> addTime (fromInteger t `div` 10) ly
otherwise -> ly
meta' = filter notOffset meta
notOffset = (/= "offset") . fst
addTime :: Int -> [LrcLine] -> [LrcLine]
addTime t = map $ \l -> l { time = (t + time l) }
嗯,还是个parseInt用来把字符串转成整数,并且很好地处理异常。
parseInt :: String -> Maybe Integer
parseInt s = case reads s of
[(int, "")] -> Just int
otherwise -> Nothing
完整代码
-- module Text.Lrc (
-- parseLrc,
-- addTime,
-- lrcAddOffset,
-- Lrc(..),
-- ) where
-- 为测试,这个被注释掉了
import Data.Char (isDigit)
import Data.Functor ((<$>))
import Data.List (sort)
import Data.Maybe (isJust, fromJust)
import Text.ParserCombinators.Parsec
data Lrc = Lrc {
title :: Maybe String,
artist :: Maybe String,
album :: Maybe String,
by :: Maybe String,
metadata :: [(String, String)],
lyrics :: [LrcLine]
}
data LrcLine = LrcLine {
time :: Int,
line :: String
} deriving (Eq, Show, Ord)
lrcParser :: GenParser Char st Lrc
lrcParser = do
metadata <- many $ try lrcMeta
ly <- concat <$> many lrcLine
return Lrc {
title = lookup "ti" metadata,
artist = lookup "ar" metadata,
album = lookup "al" metadata,
by = lookup "by" metadata,
metadata = metadata,
lyrics = sort ly
}
lrcMeta :: GenParser Char st (String, String)
lrcMeta = do
char '['
key <- many $ noneOf ":"
char ':'
val <- many $ noneOf "]"
char ']'
eol
return (key, val)
lrcLine :: GenParser Char st [LrcLine]
lrcLine = do
times <- many1 lrcTime
line <- many $ noneOf "\r\n"
optional eol
return $ map (\t -> LrcLine {
time = t,
line = line
}) times
lrcTime :: GenParser Char st Int
lrcTime = do
char '['
minutes <- readInt
char ':'
second <- readInt
centisec <- option 0 $ char '.' >> readInt
char ']'
return $ 60 * 100 * minutes + 100 * second + centisec
where readInt = read <$> many digit
eol :: GenParser Char st String
eol = try (string "\n\r")
<|> try (string "\r\n")
<|> string "\n"
<|> string "\r"
<?> "end of line"
lrcAddOffset :: Lrc -> Lrc
lrcAddOffset l = l { lyrics = ly', metadata = meta' }
where ly = lyrics l
meta = metadata l
offset = lookup "offset" meta >>= parseInt
ly' = case offset of
Just t -> addTime (fromInteger t `div` 10) ly
otherwise -> ly
meta' = filter notOffset meta
notOffset = (/= "offset") . fst
addTime :: Int -> [LrcLine] -> [LrcLine]
addTime t = map $ \l -> l { time = (t + time l) }
parseInt :: String -> Maybe Integer
parseInt s = case reads s of
[(int, "")] -> Just int
otherwise -> Nothing
main = getContents >>= \lrcfile -> case parse lrcParser "<stdin>" lrcfile of
Left err -> print err >> error "Failed."
Right lrc -> mapM_ print $ lyrics $ lrcAddOffset lrc
参考链接