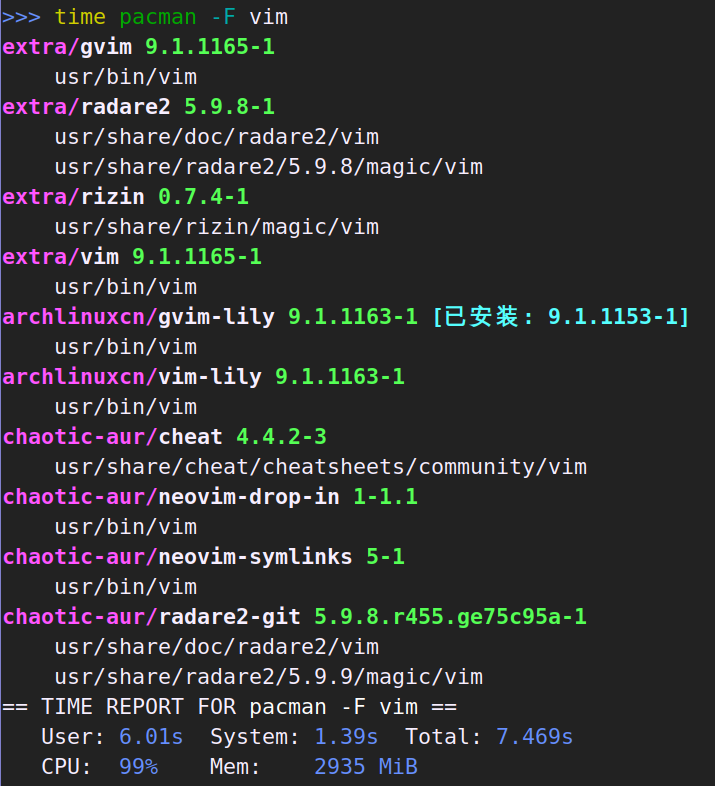
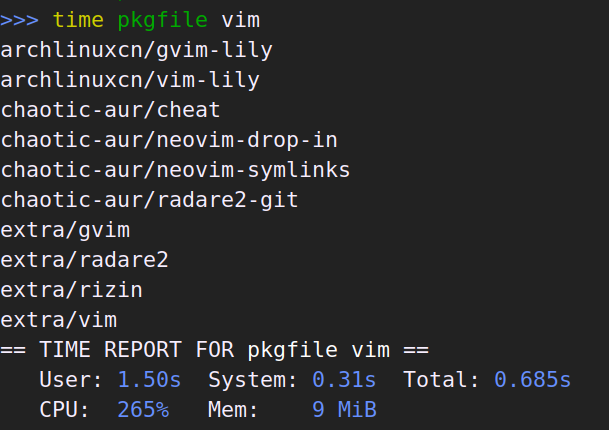
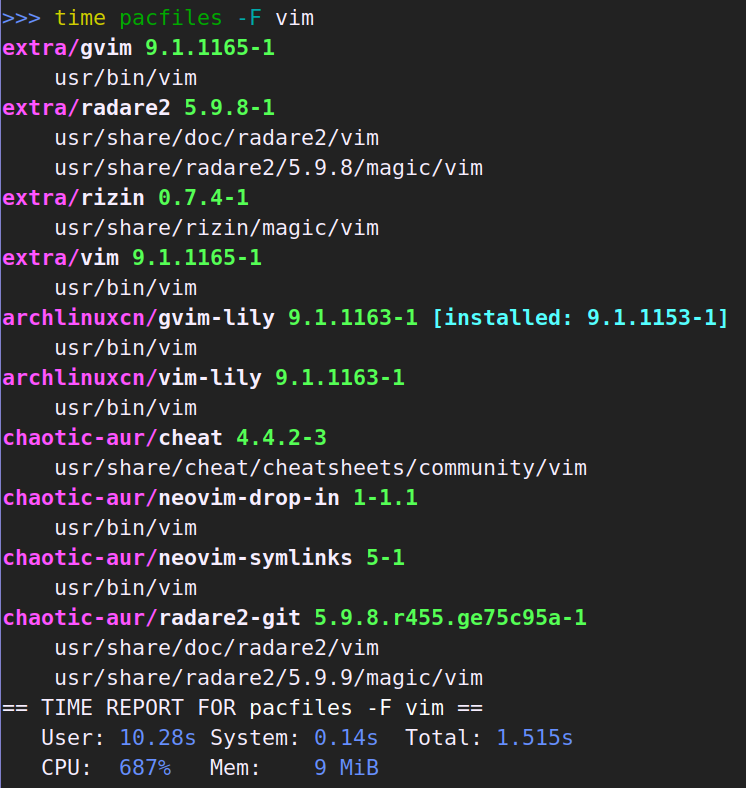
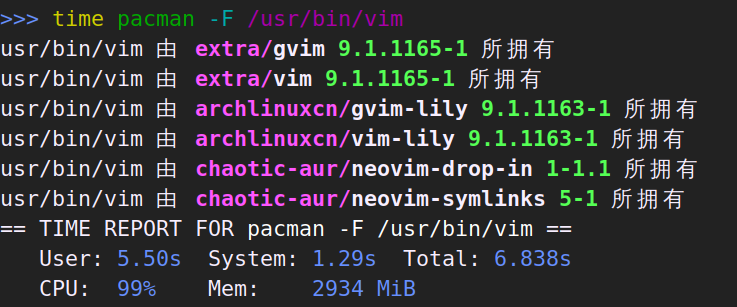
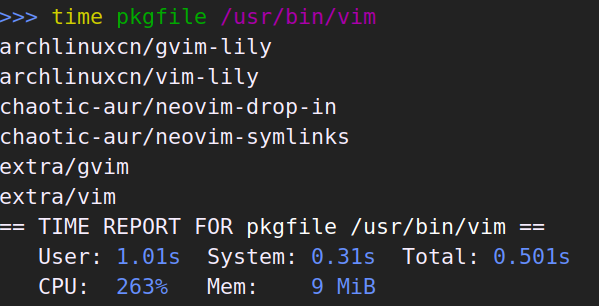
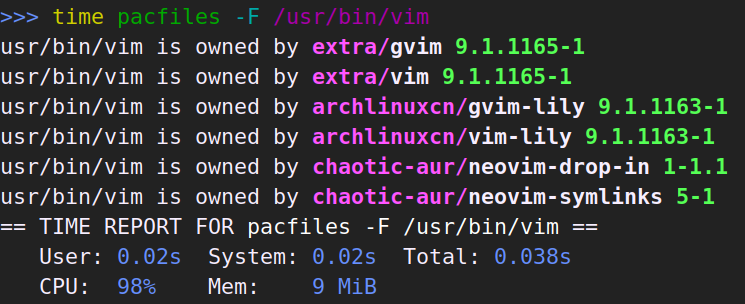
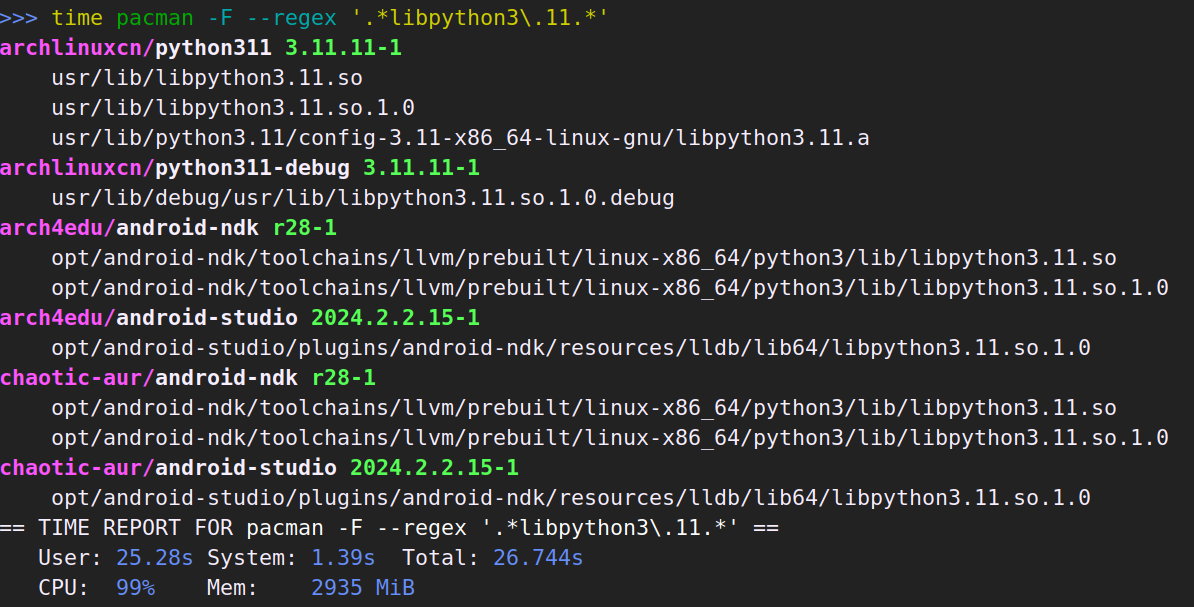
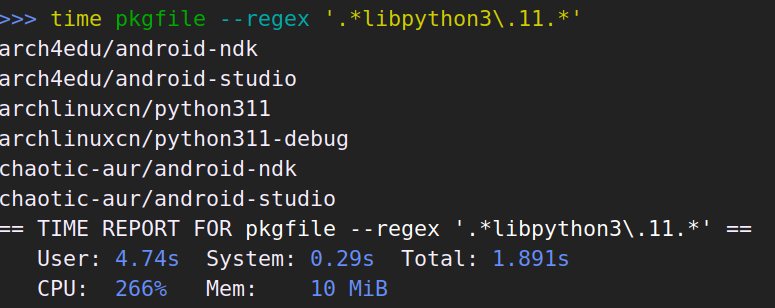
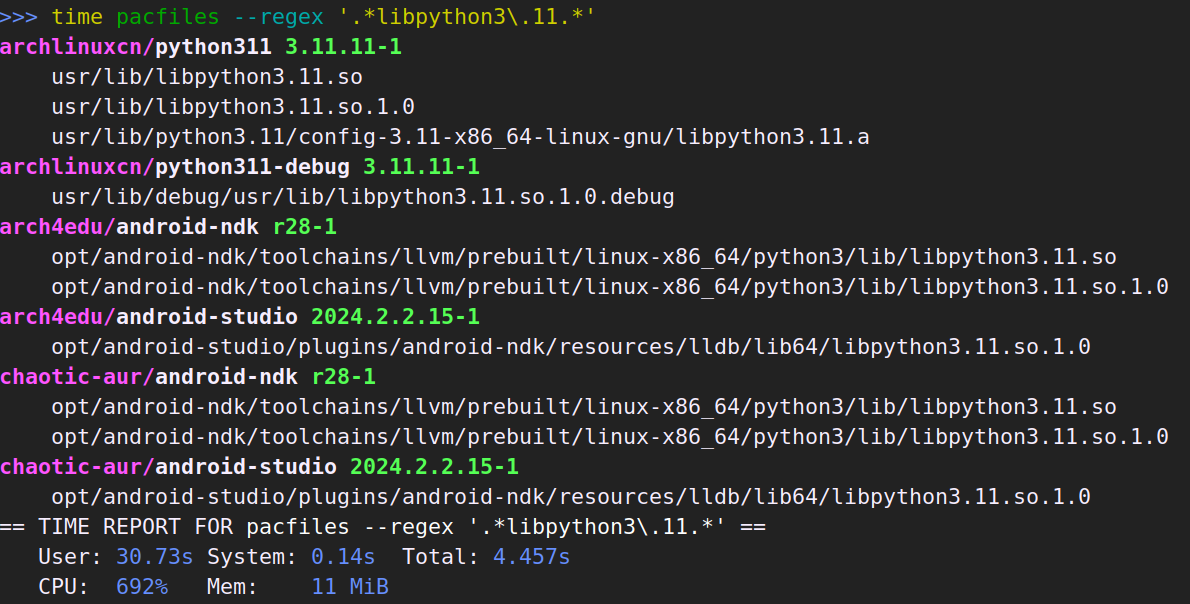
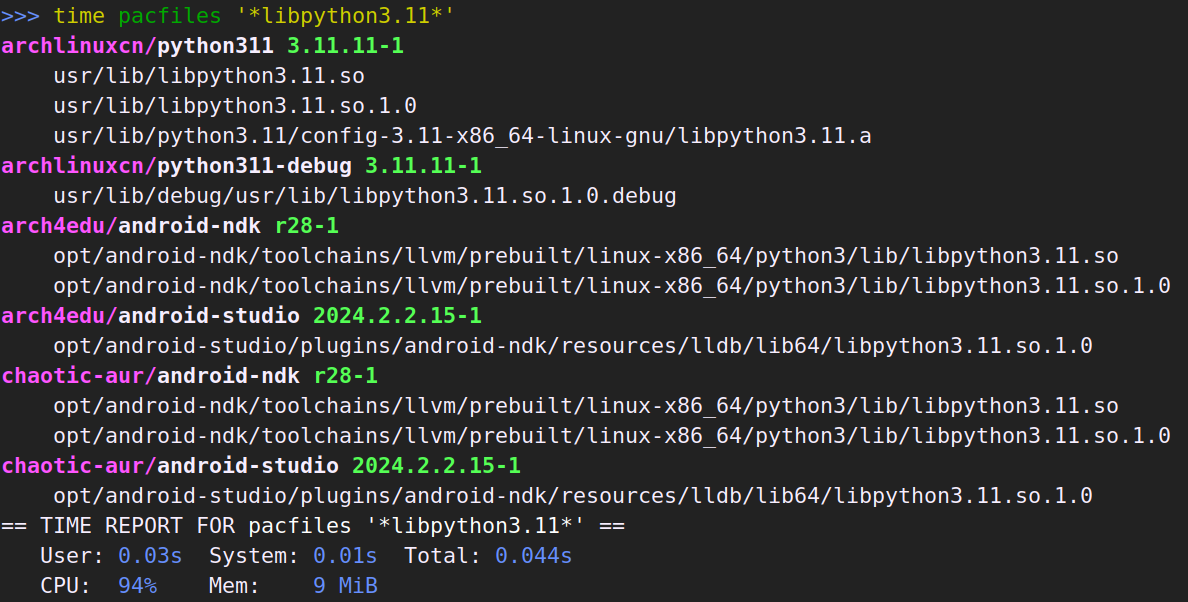
本篇只是心得体会加上赞美和吐槽。技术性的迁移记录在这里。
起
一个多月前,肥猫在 Arch Linux 中文群里说:
(希望有好心人研究一下php74,最好加到archlinuxcn里,因为咱中文社区论坛卡在这个老版本了
然后话题自然就又到了论坛迁移的事情上来——毕竟 FluxBB 年久失修也不是一两天的事了。Arch Linux 官方讨论了几年还没结果,但中文社区这边并不是卡在往哪迁上,而是
基于什么的都可以迁移,但得有人干活
然后又过了些天,论坛使用的本就递送困难的 Sendgrid 停止了免费服务,导致中文论坛完全无法注册新用户了。虽然这件事通过更改为使用我们自己的邮件服务器就解决了,但迁移论坛的想法在我脑中开始成长。
承
至于迁移到哪个软件,我早已有了想法——包括 OpenSUSE 中文社区、Debian 中文社区、NixOS、OpenSUSE、Fedora、Ubuntu、Manjaro、Garuda Linux、CachyOS、KDE、GNOME、Python、Rust、Atuin、F-Droid、OpenWrt、Let's Encrypt、Mozilla、Cloudflare、Grafana、Docker 等等(还有一堆我没有那么熟悉的就不列了)大家都在用的 Discourse。这么多开源社区和商业组织都选择了它,试试总不会错的,用户也会比较熟悉。令我惊喜的是,它甚至有个 FluxBB 导入脚本。
于是在虚拟机里安装尝试。安装过程是由他们的脚本驱动构建的 docker 镜像,没什么特别的——除了比较耗资源。Docker 嘛,硬盘要吃好几 GiB,然后它是现场编译前端资源文件,CPU 和内存也消耗不少。默认的构建是包含 PostgreSQL、Redis、Nginx 的,但 PostgreSQL 也可以用外边的,就是得监听 TCP,并且构建出来的镜像里依旧会存在 PostgreSQL 的服务文件。Nginx 可以改成监听 UNIX 域套接字,然后让外边我自己的 Nginx proxy_pass 过来,这样证书也按自己的方式管理。Redis 我本来也是想拆出来的,但是为安全起见要设个密码嘛,然后构建就失败了……不过算了,反正也没别人用 Redis。
本地测的没有问题,于是去服务器上部署。由于发现它比较吃资源,所以给服务器加了几十G内存、100G 硬盘,还有闲置的 CPU 核心也分配上去了。后来发现运行起来其实也还好,就是内存吃得比较多——每个 Rails 进程大几百,32个加起来就快 10G 了。运行起来之后 CPU 不怎么吃,甚至性能比 MediaWiki 要好上不少,以至于我把反 LLM 爬虫的机制给降级到大部分用户都不需要做了。哦它的 nginx 会起 $(nproc) 个,太多了,被我 sed 了一下,只留下了八只(但其实也完全用不上,毕竟是异步的;Rails 那些进程可是同步的啊)。
run:
- exec: sed -i "/^worker_processes/s/auto/8/" /etc/nginx/nginx.conf
说回部署。跑起来是没什么问题的。问题出在那个 FluxBB 导入脚本——本来导入就不快,它还跑到一半崩了,修了还崩。然后它不支持导入个性签名、用户头像、置顶帖,还遇到著名的 MySQL「utf8 不 mb4」的问题。来来回回修了又改,花了我好些天。等保留数据测试的时候,发现有好多帖子的作者变成「system」了。一查才发现我刻意没有导入被封禁的用户造成的。都已经配得差不多了,实在是不想删库重来,研究了一下,直接在 Rails 控制台写了段脚本更正了。这个 Rails 控制台能在 Rails 的上下文里交互式地执行代码,很方便改数据,我很喜欢,比 PHP 方便太多了!
另外这个导入脚本有一点好的是,它能够反复执行来更新数据——虽然这种支持反复执行的操作在我写的脚本里是常有的事,基本上从头开始成本太高的都会有,但别人写的脚本能考虑到这一点的可太少了。
用户的密码也导入了!帖子的重定向服务也写好了!虽然后来发现用户个人页面是登录用户才能访问的,给它重定向没什么用……反而是 RSS 重定向更有用,后来也补上了!
后来还发现有些用户名包含空格或者特殊符号啥的,被自动改名了。好在可以用邮箱认用户,不管了,等受影响的用户出现了再改。另外正式迁移之后才发现还有些数据没有迁移——版块的对应关系、用户的主题订阅,不是很重要,算了。
转
然后就迁移结束啦~所有到旧论坛的访问全部重定向到新论坛啦~不过我还是保留了一个不跳转的后门以便有需要时回去看看。为此我折腾了好久神奇的 nginx 的配置文件,最终得到以下片段:
set $up 'redir';
if ($http_cookie ~ "noredir=1") {
set $up 'noredir';
proxy_pass https://104.245.9.3;
}
if ($up = redir) {
proxy_pass http://127.0.0.1:9009;
}
就是根据 cookie 来 proxy_pass 到不同的服务啦。这样就可以访问一下 /noredir 设置上 cookie,就可以访问旧论坛,再访问一下 /yesredir 清一下 cookie 就恢复跳转到新论坛了。
说起 nginx,Discourse 还在这方面坑了我一下。它文档里给的设置是:
proxy_set_header Host $http_host;
这个配置在 HTTP/3 时是坏的,应该用 $host。别问我 HTTP/2 也没有 Host 头啊,为什么它在用 HTTP/2 时就不会出错。我也不知道 ¯\(ツ)/¯。
于是新论坛上线啦~很多中国大陆用户的首次加载时间变成几十秒啦……还好这只是无缓存加载的时间,就当是下载软件了吧。之后每个标签页大约需要一两秒加载整个 SPA,在不同页面之间跳转并不慢。而这代价付出之后的回报是更现代的界面、丰富的功能。相比于旧论坛,现在:
-
终于有手机版啦,甚至还支持 PWA,体验非常丝滑。
-
实时预览的 markdown + bbcode 编辑器,还支持上传图片!再也不会有用户问论坛怎么传图片和日志了!
-
编辑器还支持草稿功能!不用怕写一半弄丢了,甚至可以换个设备接着写。
-
代码块角落里有个复制按钮,我再也不需要拖半天鼠标来复制日志然后粘贴进 Vim 里分析了!
-
快速、简单的搜索体验,用户再也不会找不到搜索功能在哪里了!
-
实时显示在回复的人。有人在回复的时候就可以等一等,发布帖子之后会立刻出现。发帖不需要跳转到不知道干什么的跳转页面了,读帖也不需要反复刷新了。
-
有收藏功能了,用户不用发一个根本没什么用的「mark 一下」的帖子了。
-
有「标记为已解决」的功能了。用户再也不需要问怎么把帖子标记为「已解决」了。
-
不用自己跑脚本解析 HTML 来向群里发新帖通知了。Discourse 的「聊天集成」功能配一下就好了。
-
甚至还有「RSS Polling」插件,可以把主站新闻转到论坛里,方便大家讨论。
Discourse 的邮件集成功能也挺不错的。配好之后,可以检测到退信,也可以直接回复邮件通知来回帖。甚至还有个邮件列表模式,就是把所有帖子都给用户发一遍,用户也可以直接回帖。通过邮件发布新主题的功能也有,但我没有启用——不同版块需要配不同的收件地址,有点麻烦,我不觉得有人会想用……就是这个邮件传回 Discourse 部分坑了我一把,但不是 Discourse 的错。
是 maddy 的文档太缺欠了。我要把 forum+...@archlinuxcn.org 这种地址给重写到 noreply@archlinuxcn.org,按例子像这样
table.chain local_rewrites {
optional_step regexp "forum\+(.+)@(.+)" "noreply@$2"
optional_step regexp "(.+)\+(.+)@(.+)" "$1@$3"
optional_step static {
entry postmaster postmaster@$(primary_domain)
}
optional_step file /etc/maddy/aliases
step sql_query {
driver postgres
dsn "user=maddy host=/run/postgresql dbname=maddy sslmode=disable"
lookup "SELECT mailname FROM mailusers.mailinfo WHERE $1 = ANY(alias) and new = false"
}
}
这里第二行是我加的(虽然一开始把 $2 照着下边那个已有的写成了 $3)。结果是报错「用户不存在」、被退信。我开 debug 选项研究了好久,才意识到最后一步写的是 step,所以它总是要执行的——然而 noreply 这个用户并不在数据库里,所以就找不到了。
那把最后一行改成 optional_step 就好啦——我是这么想的,也是这么做的。然后就有人报告说 admin 邮箱拒收邮件了……又是一通研究,才发现因为这里的步骤全是 optional_step,所以 maddy 第一次用整个邮件地址来查的时候,无论如何都是会通过的——不会返回「目标不存在」,所以也就不会触发去掉域名、只用用户名查询的步骤,而数据库里记录的只有用户名,就导致 admin 邮箱的映射查不到了(映射到它本身,然而并没有以它为名的邮箱)。把 SQL 查询那一行改成这样子就好了:
lookup "SELECT mailname || '@archlinuxcn.org' FROM mailusers.mailinfo WHERE regexp_replace($1, '@archlinuxcn.org$', '') = ANY(alias) and new = false"
然后是把收件的邮件交给 Discourse。他们有个 mail-receiver 容器用来干这事,但这个容器的主要部分其实是 Postfix。我读了一下它的代码,实际上只需要把邮件通过 API 发过去就行了。于是我用 Python 写了一个服务——imap2discourse。这部分的坑在于,这个 API 是把邮件全文用指定的参数 base64 或者不 base64 用 form-data 传过去的,我以为是用上传文件的方式来传,搞了半天它都报奇奇怪怪的错,后来一步一步在 irb 里按 mail-receiver 的代码对照检查,才发现原来是按传字符串的方式传的……
Discourse 的中文翻译不怎么样,好多随意的空格,也好多看不懂的翻译。好在它像 MediaWiki,支持修改界面文本。于是就一点一点地修了好多。上游使用的是 Crowdin 翻译平台,并不能直接 pr 翻译,所以等我什么时候研究一下才能把翻译贡献给上游了。
Discourse 的通知功能挺全面的。可以选择回帖之后要不要通知,邮件通知是只在没访问时发、完全不要还是全都要,网站图标上要不要显示通知计数,还可以开启浏览器的推送通知(然后我就发现 Android 火狐的推送通知无法切换到 PWA 窗口)。
至于管理功能,比 FluxBB 丰富好用太多啦~有各种访问统计报表。设置项有搜索功能。有管理员操作日志,也有选项变更日志,还有邮件收发日志(看看谁又把自己的邮箱域名拼错了)。能给用户添加备注,也能切换成指定的用户看看他们看到的论坛是什么样子的。能给用户添加字段,让用户填写他们用的操作系统和桌面环境,省得回帖时经常要询问。还能加载自定义的 JavaScript 和 CSS,甚至是加强版本。还有暂时用不上的 API 和 webhook。哦对了,我发现它还会自己拒绝一些常见的讨厌爬虫。
合
除了 FluxBB 之外,还有一个叫 planetplanet 的 RSS 聚合软件也是死了好多年,导致 planet.archlinuxcn.org 多年不更新了。Discourse 正好有从 RSS 发帖的功能,于是将星球也复活了一下,将大家的 RSS 作为帖子在专门的版块发出。虽然界面不是很理想,但将就着用啦。RSS 聚合也是有的。Discourse 的 RSS 功能相当完善,几乎在所有合理的网址后边添加 .rss 就能订阅。
也给旧论坛做了个静态存档站。暂时还没上线,因为肥猫又跑掉了。
Discourse 的备份功能会报错,因为它的容器里的 pg_dump 版本比较旧,和我在外边 Arch Linux 里运行的版本不一致。不过我觉得这样也挺好的——因为管理员是可以生成和下载备份文件的,也就是说,如果有管理员的权限被人恶意获取,那么他就能通过下载备份文件的方式获取整个 Discourse 数据库的内容。备份不了就少了这么个风险啦。当然备份我肯定是做了的,至于是如何做的,就等下一篇啦。