前些天尝试了一下 KDE 桌面环境,不过实在是没能用下去。
首先要说的是,KDE 桌面确实漂亮,非常养眼。设置项也挺多,可定制性还是挺不错的。只可惜问题同样很多。
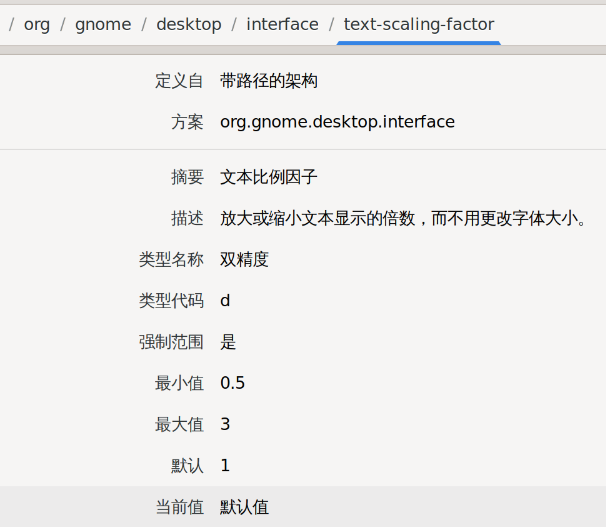
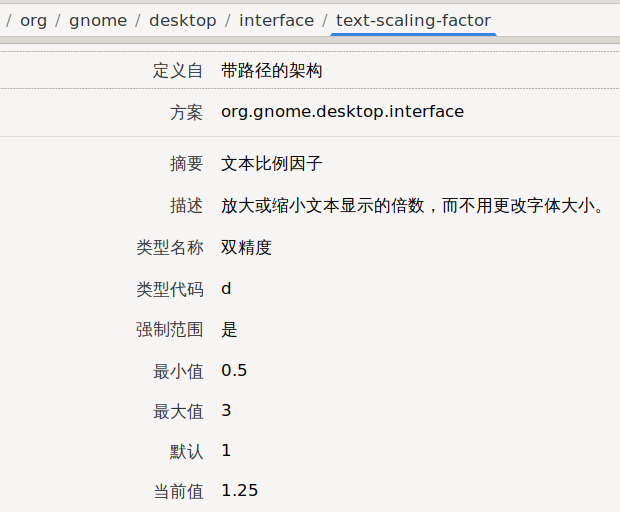
首先是显示器缩放的问题。受限于 X11,KDE 只能设置一下全局的缩放比例。所以我们只好缩放显示器显示的画面。不幸的是,一向相当体贴的 KDE 此时却笨笨的,在使用 xrandr 设置好之后需要重启 plasmashell 来使其获取 xrandr 的设置更新:
kquitapp5 plasmashell && kstart5 plasmashell
KDE 的设置项很多,分门别类地在「设置」应用程序中集中列出来,然而问题也由此产生:同时只会显示一个「设置」窗口。也就是说,我配置快捷键时,想去窗口管理器那边看一看,调整一点选项,就必须放弃我当前打开的快捷键视图,放弃我键入的搜索词,并且选择「应用」或者「放弃」更改,才能切换到另一个「设置」组件中去。即使从 krunner 里打开某个组件的设置,它也会找到并更新已有的窗口。
我知道 Windows 10 也是这么个「单任务」设置的风格。可 Windows 10 也没有这么多可以设置的地方呀。后来获知有个命令可以打开单独组件的设置窗口。很不方便。它被隐藏起来的原因是这种窗口不能返回到组件列表界面,会让用户困惑。可是,为什么我不能同时打开「设置」的不同组件的多个窗口?单独组件的窗口会让用户困惑,那就不要用单独组件的窗口就好了嘛。
KDE 桌面还有个问题:启动特别慢。登录进入界面要好久,启动一个程序,它的图标也要跳好久窗口才会出现。不知道它在干什么。我甚至怀疑它是为了展示启动动画而故意推迟界面的显示。
KDE 有提供丰富的桌面部件。我往副显示器上放了一些系统状态的监视器——CPU、磁盘、网络啥的。然后问题来了:我凑齐了四个部件刚好形成2x2的网格,可是我要怎么对齐它们呢?并没有对齐的选项,也没有吸附的功能。在我找到它使用的配置文件并手动修改之前,我只能用肉眼瞅。可计算机不就是用来做这种人不擅长而机器擅长的事情的吗?
终端我还是用 GNOME Terminal,因为有些特性(比如超链接)只有它支持。但又出现问题了:它启动之后,pin 它的任务图标,或者通过任务栏图标创建新实例均会失败。把它 pin 到任务栏上,需要从主菜单的右键菜单里操作。即使这样,启动之后终端窗口还是会位于新的图标,旧图标还是不对应任何窗口。后来查了一下,GNOME 的东西都没有主动支持启动通知,导致 KDE 很多时候只能猜测,而这次它猜错了。解决的办法是给 GNOME Terminal 的 .desktop 文件加上正确的 StartupWMClass 项。这其实不是 KDE 的问题,但也没办法。KDE 不想为别人擦屁股,GNOME 不在意自己的软件在别的桌面上的可用性。
不过 Qt 写的 flameshot 我就不知道是怎么回事了。具体情况不记得了,反正就是显示异常。好像是全黑吧。我没来得及 debug 这个。
最后,让我决定放弃 KDE 的点来了:我设置不了我需要的窗口管理快捷键。
切换窗口,默认是 Alt-tab 的那个,我好不容易在「快捷键」设置里找到了添加更多快捷键的方式,但我发现除了 Alt-tab,我自定义的都不能连续切换窗口。按一下,切换一下,然后就切不动了,只能放开快捷键。后来了解到这是设置更新方面的问题,kwin_x11 --replace一下就有效了。
切窗口其实问题不大。问题大的是切显示器屏幕。两个功能:一、把焦点切到另一个屏幕;二、把当前窗口移到另一个屏幕上。
前者可以勾选「分隔屏幕焦点」选项,然后调整一下「阻止盗取焦点」的级别。我也不知道这个级别都是啥意思。「无」我能理解,「低」「中」「高」「终极」都是些啥?反正调整一下,确实可以把窗口焦点切换到另一个屏幕去了,除了鼠标不会跟着过去!另外测试过程中,有时候焦点会丢失——我不知道当前什么窗口获得了焦点,也不知道接下来谁会获得焦点。比 Mac OS X 里焦点跑到一个窗口也没有的 Finder 上还要神秘。
不过这个倒是可以自己写个脚本解决:使用 xrandr 获取屏幕的大小和位置,通过 X 的接口获取鼠标的位置并通过 Xtest 扩展来移动它,然后再用某个 X 的接口去设置窗口焦点——完全绕过 KDE 的功能。
然后我被另一个问题难住了——我怎么把窗口移到另一个屏幕上并且把焦点也移过去呢?使用文档匮乏的 kwin script 是可以把窗口移过去,然后我没能找到移动鼠标光标的 API。通过 X 是可以移窗口的同时移鼠标,但是我拿不到带窗口装饰的窗口位置信息。kwin 有一个 getWindowInfo 的 D-Bus 接口,但是它接收的那个 UUID 参数,我没找到获取的方法。
总结一下,KDE 对快捷键的支持并没有想像的那么好,尤其是多显示器的支持。快捷键的设置是通过图形界面来操作的,虽然直观但是对于大量快捷键的管理来说非常困难。而对于大显示器来说,通过快捷键来管理窗口是十分必要的——因为我更难肉眼找到我的鼠标光标去了哪里。
接下来,我打算一边忍受着 Awesome 3.5.9 的旧与 bug,一边尝试将 i3 改造成我需要的样子。