很早之前,我在《Linux「真」全局 HTTP 代理方案》中介绍了 redsocks 方案。不过它只处理了 TCP,并没有处理 UDP,DNS 也是采用强制 TCP 的方式来处理的,再加上它本身还要将请求转发到真正的代理客户端,延迟比较高。然后,还可以结合 Wi-Fi 分享 或者网络命令空间,玩点更有趣的。
首先要有支持的代理客户端,比如 ss-redir。这个就不用多介绍了,配置好、跑起来即可。以下假设此代理跑在 127.0.0.1 的 $PPROT 端口上。
然后,TCP 的代理设置。使用的是和 redoscks 一样的方案。这个比较简单,除了有一点需要注意:DNAT 到 127.0.0.1 时,需要设置内核选项net.ipv4.conf.all.route_localnet=1。
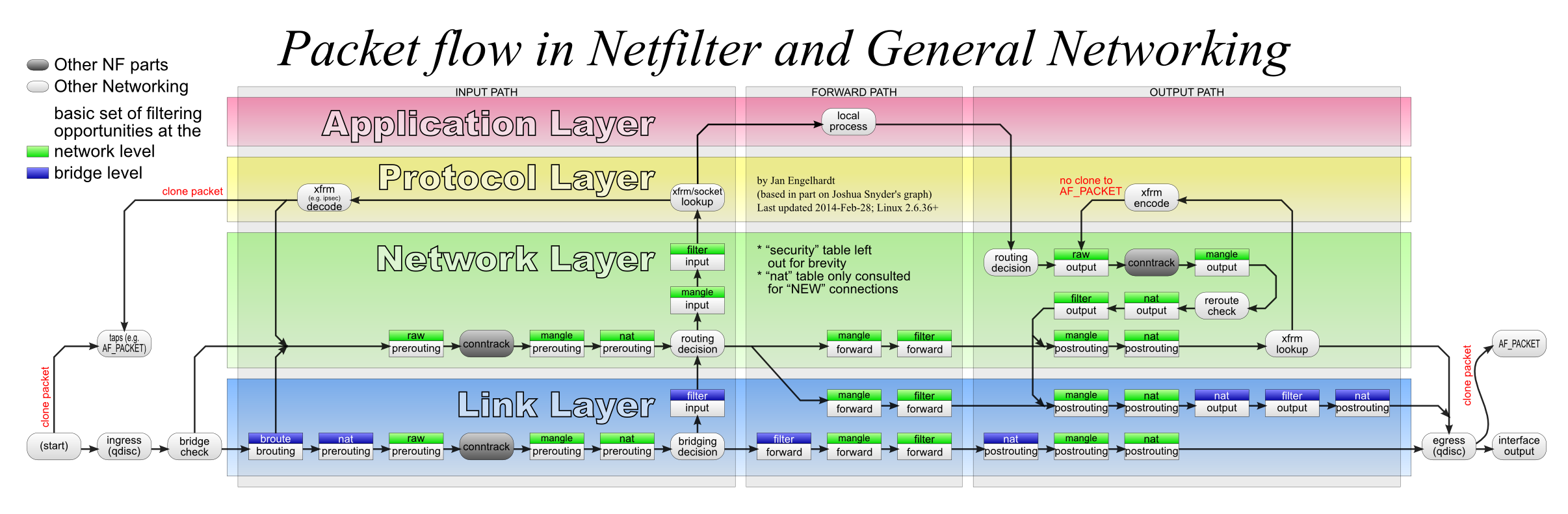
最麻烦的是 UDP 的代理,使用的是 TPROXY。首先,需要把要走代理的数据包路由到本地。以下假设我们给要代理的数据包打上标签 1。那么执行:
ip rule add fwmark 1 lookup 100 ip route add local 0.0.0.0/0 dev lo table 100
那个 100 是路由表的编号,可以自己选一个喜欢的。
然后,对于转发流量(来自局域网或者另外的网络命名空间),直接把需要代理的数据包扔给 TPROXY 目标,并且打上对应的标签即可。而对于本地产生的流量,不仅要带有对应的标签,而且需要在 OUTPUT 链打上一个(与之前不同的)标签,触发 reroute check 才行。
最后,对需要代理的数据包设置 iptables 规则:
| 协议 | 来源 | 表 | 链 | 目标 |
|---|---|---|---|---|
| TCP | 本地 | nat | OUTPUT |
-j REDIRECT --to-ports $PPROT |
| 转发 | PREROUTING |
-j DNAT --to-destination 127.0.0.1:$PPROT |
||
| UDP | 本地 | mangle |
OUTPUT PREROUTING |
-j MARK --set-mark 1-j TPROXY --on-port $PPROT --on-ip 127.0.0.1 |
| 转发 | PREROUTING |
-j TPROXY --on-port $PPROT --on-ip 127.0.0.1 --tproxy-mark 1/1 |
比如来自网络命名空间或者局域网的 IP 段 192.168.57.0/24 全部走代理:
iptables -t nat -A PREROUTING -p tcp -s 192.168.57.0/24 ! -d 192.168.57.0/24 -j DNAT --to-destination 127.0.0.1:$PPROT iptables -t mangle -A PREROUTING -p udp -s 192.168.57.0/24 ! -d 192.168.57.0/24 -j TPROXY --on-port $PPROT --on-ip 127.0.0.1 --tproxy-mark 1/1













{kind=link}