用上 Awesome 3.5 后,我发现 Awesome 占用的内存有点多。后来又发现,运行的时间越长,其占用的内存也就越多:

这不是典型的内存泄漏吗!
然后我发现我只要按下Win+Ctrl+R重新载入 Awesome 配置,内存使用就会回去。看来是我的配置文件有问题。不过由于时间关系一直使用重新载入的方式应付着。今天终于有点时间和兴致,于是专心对付它了。
不过 Lua 脚本的内存泄漏要怎么查呢?我一开始想把_G打印出来。不过以前写的那个 Lua 对象转字符串函数似乎并不太喜欢 Awesome 加进去的那些对象,抛出了异常。瞪大双眼检查配置文件里的各种全局变量,特别是那里每隔几秒更新一次的指示器们,但也没发现什么。有些不知所措,随手又调出 htop 查看上图中那个占用了「巨量」内存的 Awesome 进程,右手无名指不自觉地按下,然后竟然发现了一个问题:
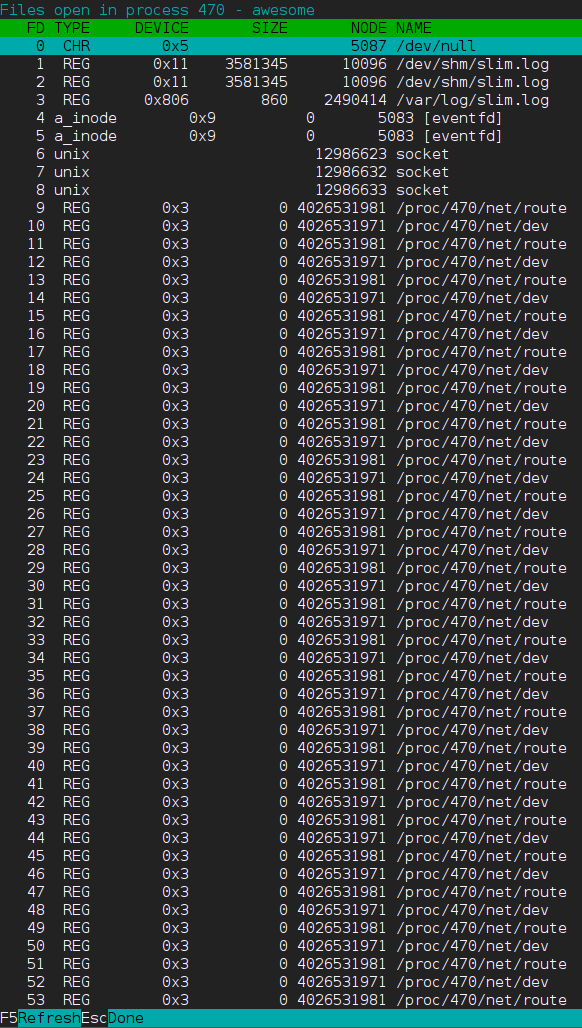
怎么开了那么多/proc/net/route和/proc/net/dev文件?这两个文件是我在网络指示工具中打开并读取了的,但是我不至于扔着打开的文件不管啊:
function update_netstat()
local interval = netwidget_clock.timeout
local netif, text
for line in io.lines("/proc/net/route") do
netif = line:match('^(%w+)%s+00000000%s')
if netif then
break
end
end
if netif then
local down, up
for line in io.lines("/proc/net/dev") do
-- Match wmaster0 as well as rt0 (multiple leading spaces)
local name, recv, send = string.match(line, "^%s*(%w+):%s+(%d+)%s+%d+%s+%d+%s+%d+%s+%d+%s+%d+%s+%d+%s+%d+%s+(%d+)")
if name == netif then
if netdata[name] == nil then
-- Default values on the first run
netdata[name] = {}
down, up = 0, 0
else
down = (recv - netdata[name][1]) / interval
up = (send - netdata[name][2]) / interval
end
netdata[name][1] = recv
netdata[name][2] = send
break
end
end
down = string.format('%.1f', down / 1024)
up = string.format('%.1f', up / 1024)
text = '↓<span color="#5798d9">'.. down ..'</span> ↑<span color="#c2ba62">'.. up ..'</span>'
else
netdata = {} -- clear as the interface may have been reset
text = '(No network)'
end
我是用io.lines函数打开文件的。印象中这家伙是会自动关闭文件的啊,我也没办法再手动关闭是不?不过既然是这地方的问题,那么再去仔细看看文档好了:
Opens the given file name in read mode and returns an iterator function that works like file:lines(···) over the opened file. When the iterator function detects the end of file, it returns nil (to finish the loop) and automatically closes the file.
什么?and automatically closes the file
?也就是说如果文件没读完的话……
于是我立即打开 ilua 写下:
for i in io.lines('strprint.lua') do print(i) if i:sub(1,1) == '-' then break end end
执行完毕,再去 htop 里查看文件描述符,果然没关!
好吧,又一坑。于是改成像 C 语言中那样显式打开和关闭文件了(相关提交在此)。过几天再看看问题有没有完全解决。
2014年1月11日更新:后来还是依靠 inspect.lua 才完全解决我的 Awesome 配置中的内存泄漏。