以前这服务器就经常被 OOM Killer 大开杀戒,各种服务都被杀害。虽然早就通过日志和其它信息知道是 npm 惹的祸,今天才有幸看到如此疯狂的 npm(点击查看大图):
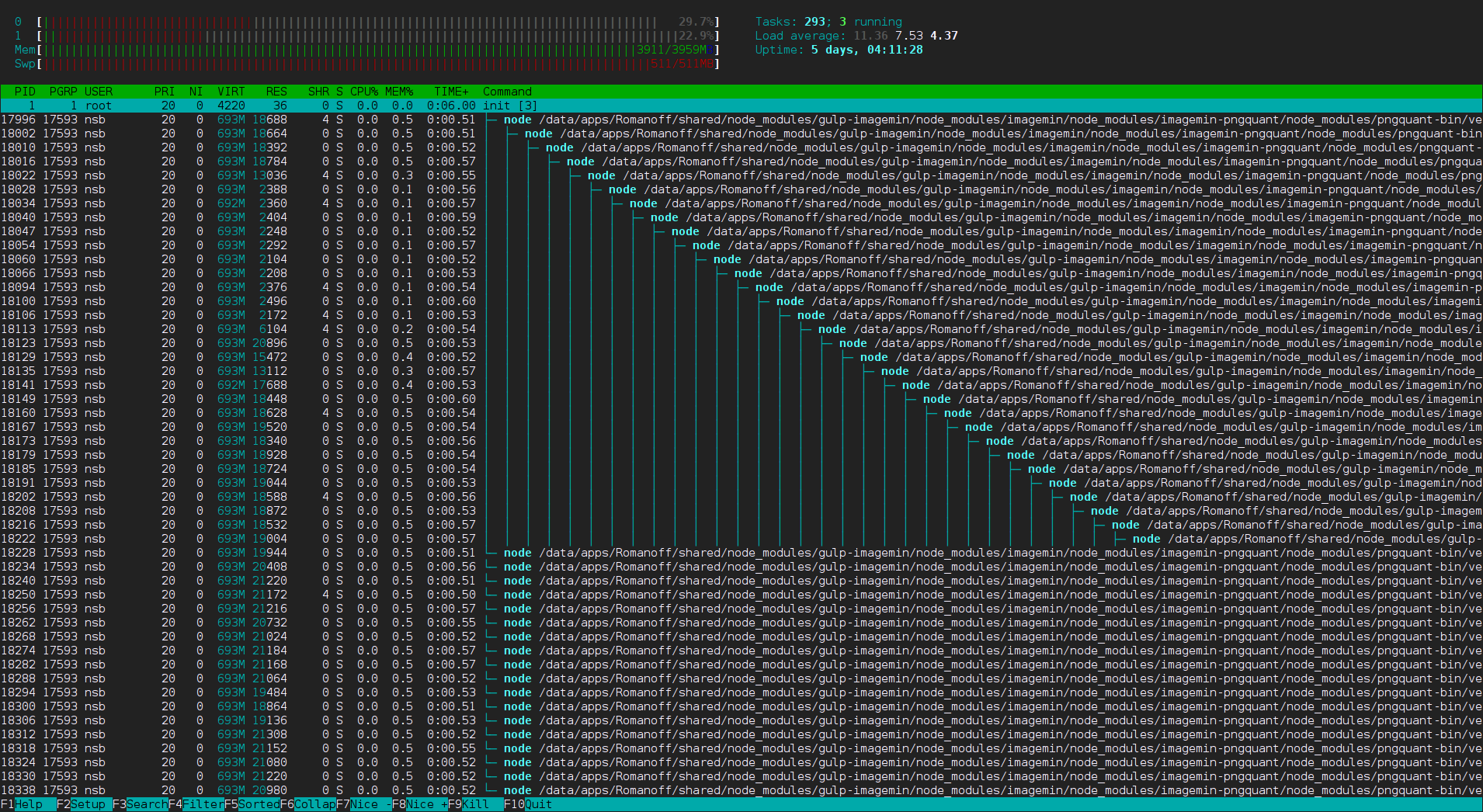
说明一下,此 npm install 是正在安装 gulp 相关的东西。在本地跑的时候倒是没发现 npm 有如此「牛力」,只是比较费时费内存而已,不知道在这服务器上是发了什么疯。
以前这服务器就经常被 OOM Killer 大开杀戒,各种服务都被杀害。虽然早就通过日志和其它信息知道是 npm 惹的祸,今天才有幸看到如此疯狂的 npm(点击查看大图):
说明一下,此 npm install 是正在安装 gulp 相关的东西。在本地跑的时候倒是没发现 npm 有如此「牛力」,只是比较费时费内存而已,不知道在这服务器上是发了什么疯。
这是偶然间发现的。在 GitHub 桌面版网页上,按第一下 Tab 时,会在左上角显示一个「Skip to content」的链接,并且键盘焦点就在这里:

我被这样的小小地惊艳了一下。这个链接可以用来跳过不怎么常用的导航栏上那排链接和按钮。
作为经常打字聊天和写码的人,在电脑前的大部分时间手当然是在键盘而不是鼠标上,所以使用鼠标来进行一些操作很常见。虽然我有 keynav 和 VimFx 来辅助,但是见到 GitHub 这么贴心的细节还是挺喜欢的。
这让我想起了国内的网址,大部分都根本不考虑 accessibility。比如问答社交网站知乎。我早已不「逛」知乎了,只是收到感兴趣的邀请时去看看。因为知乎的体验实在是太差劲了。
知乎取消了所有链接在获取焦点时周围的虚线。这意味着根本没办法使用键盘导航,因为你不知道当然焦点在哪里。
知乎的提交按钮完全无法使用键盘操作。看看 GitHub,写好评论什么的,按一下 Tab 焦点就去了提交按钮上,并且有非常明显的反馈。按空格或者回车就可以提交。如果决定放弃,再按一下 Tab 就好。这两个按钮的顺序是按使用频率而不是相对位置来获取焦点的,因为提交显然比放弃用得更多。Twitter 发送新消息、Google+ 评论的提交按钮也是这样。不过 Twitter 偶尔会需要按两次 Tab 才能提交,大概是改页面的时候不小心给改坏了,过段时间会修好。Google+ 分享新信息时会比较讨厌,因为要跳过好大一堆「添加照片」什么的按钮。
类似的 accessibility 处理,国外著名网站上经常能看到很好的实践,博客上经常能看到大家在关心「少数用户」的使用便捷性。而国内很少有关注这方面的,大家都跟乔布斯一样想,「不管合不合理,我是这么设计的所以你应该这么用」。
比如验证码。不管需不需要,都是字符图。这样盲人就用不了。而国外广泛使用的 Google reCAPTCHA 就可以选择通过声音收听验证码。当然是英语的。反正这全球最大的网站之一已经消失在中国大陆人的视野之中了。我知道专门有人建立了一个 QQ 群,视力正常的人帮助盲人识别验证码用的。
这大概是发达国家与发展中国家的侧面写照的缩影了吧。
最后扔一堆链接:
很久以前的事情了。现在终于不再感觉到那么累了,想写,所以才写。权当日记吧,就懒得加各种链接和排版了。
这次的面试目标是百度运维工程师。
问题:为什么 Arch Linux 中文社区源的自动打包服务是自己弄的,而不使用现成的 CI 呢?
其实原因很简单:没想到。因为 lilac 自动打包脚本是由功能更简单、自动化程序也更低的脚本进化而来的,比如 nvchecker 更新、曾经自己用过的一些辅助脚本等。
当然,即使想到了,我也不会去用的,因为需要定制的东西太多。更新检查、依赖处理、错误回报、git 仓库管理什么的。传统的 CI 不像是天生支持这些的。最接近的 OBS 大家也知道,对 Arch 的支持很差。当然我可以进行二次开发,但工作量会很大、耗时会很长,因为那是我需要从头读文档、学习、尝试的一套系统,而对于 Linux 编程、Python 编程,我已经非常熟悉了。至于可重用性?首先我要解决它的可用性,东西都做不出来了,何谈可重用性呢?
当然 CI 系统对资源的消耗也不能忽视。
这个问题挺意外的,面试的时候没想这么清楚,没答到重点。
问题:为取得网站的高可用性,防止单个服务器挂掉影响整个服务,要怎么办呢?
我的回答是通过 DNS 和 anycast fallback。哪个服务器挂掉了就不用哪个了。DNS 的更新有些慢,在 DNS 应答中返回多个 IP 地址用处不大,大部分客户端都只会尝试第一个,我见过的只有 wget 会锲而不舍地穷尽一切方案去努力。Anycast 反应会更及时一些,CloudFlare 就喜欢用这个。
但是标答是 LVS。好吧这个词我没研究过。回来上网去看了一下,Linux Virtual Server,就是在前端放个负载均衡啦。我没有想到这个。今天我终于想到我为什么没有想到这个了——LVS 还是一台服务器嘛,只是逻辑上的服务器。作为一名程序员和数学爱好者而不是电器维修工,我对各种物理上的东西没什么深刻印象,反而对各种抽象的概念情有独钟。所以我自然而然地把「单个服务器」理解成单个逻辑上的服务器了,而不是或大或小的铁盒子。也就是说,我的理解是,当这个 LVS 系统挂掉了要怎么办。
我再一次把面试官想得到的答案当成了理所当然……
问题:正在进行通讯的两台主机之间的「网线」断了,一方再发送数据,这时会发生什么?
这个问题也很不明确,存在多种可能。
最简单的,直接连接发送方的网线断掉了。内核会收到硬件传回的信息,「carrier lost」,然后相应的路由表项被删除。就跟把相应的网络设备 down 掉一样。什么都不会发生,连重试都没有。应用程序就在那儿等着。
如果是位于局域网中,情形也差不多。只是会进行 TCP 重试,然后 ARP 广播「找人」。
互联网上的话,如果还有其它线路可用,数据包会走其它线路。如果所有线程都不通了,应该会返回 ICMP 主机不可达或者网络不可达。不知道这种情况下 TCP 和应用程序会发生什么。没条件实验。学校网络课实验自然不可能搞这么「高端」的东西。
当然,这么些可能我当时也没想全。
我发现我面试的时候思考能力变得很差的样子。其实凡是被人关注的时候都会发挥失常,虽然没有严重到别人盯着就写不出代码来。这也是我在社交活动常不满意的原因吧。
GitHub 用户页有个 calendar,花花绿绿的甚是好看。不过,经常一不小心断掉了几十天的 steak 着实可惜,特别是用了私有仓库之后,自己看,有贡献,可别人看不到那些私有贡献的呀。其实要维持 steak 也不难,一个小小的提交就足够了——只要我知道我今天还没 push 什么公开的东西的时候。
当然啦,写个脚本天天推个无意义的更新挺容易的,但那样就没有乐趣了不是吗?一天快结束的时候发封邮件提示一下自己不错,但可能已经来不及了。而且这种事情还是随意点好,太刻意了就不好玩了,所以不需要那么强的提醒。弄一个简单的指示器在 Awesome 面板上正好。
效果图(指示器在右上角):
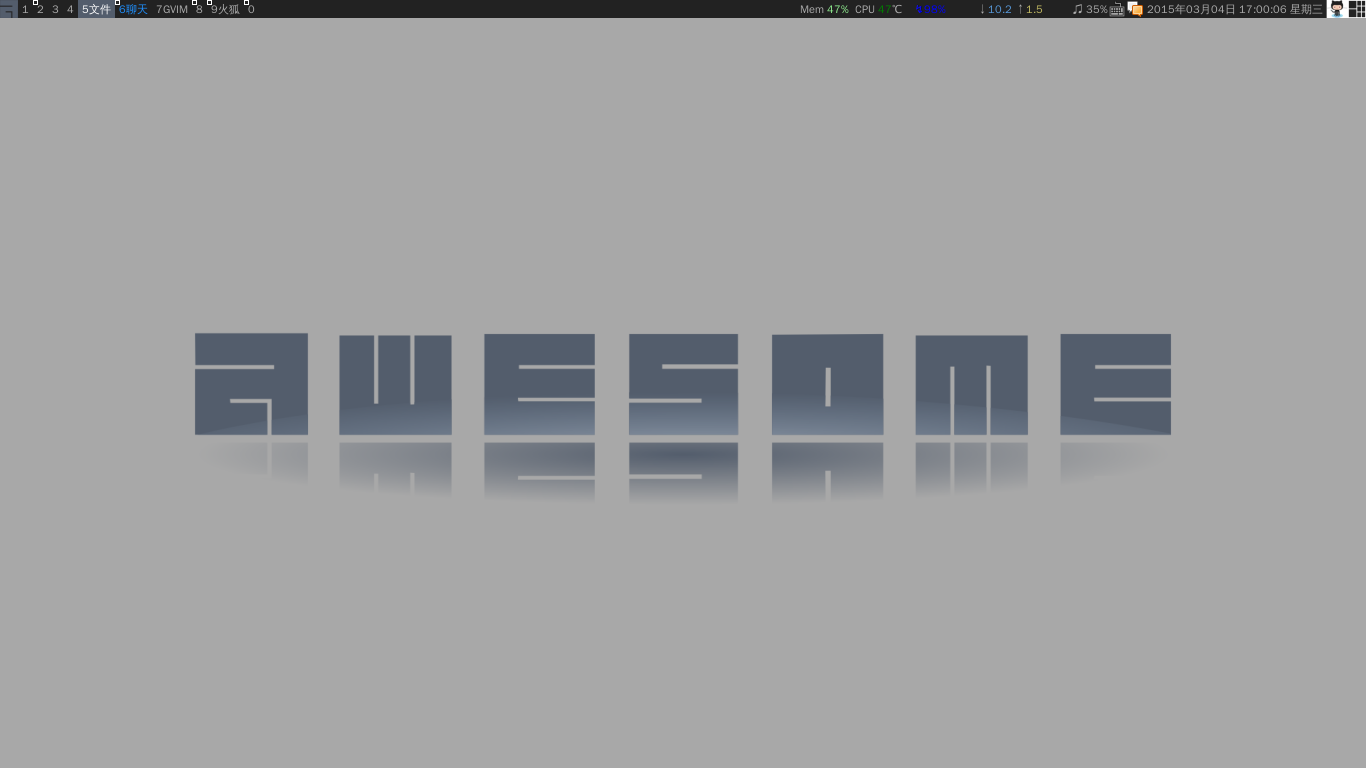
如果这天没有贡献(公开的提交或者 issue 等),那么这只 Octocat 就会失去色彩(变成灰度图)。
代码已上传至 myawesomerc 仓库。以下是实现细节:
首先,创建一个显示图片的 widget:
-- {{{ GitHub contribution indicator
github_contributed = awful.util.getdir("config") .. "/image/github_contributed.png"
github_not_contributed = awful.util.getdir("config") .. "/image/github_not_contributed.png"
github_widget = wibox.widget.imagebox()
function update_github(has_contributions)
if has_contributions then
github_widget:set_image(github_contributed)
else
github_widget:set_image(github_not_contributed)
end
end
update_github(false)
-- }}}
-- 在 wibox 中添加这个 widget,需要放到正确的地方:
right_layout:add(github_widget)
函数update_github是给外部脚本用的。不可在 Awesome 配置里直接发起 HTTP 请求,会阻塞的!
当然,还要准备前两行代码提到的图片。从这里下载 Octocat 的图片,并做成彩色和灰度小图:
convert -resize 48x48 -background white -alpha remove Octocat.png github_contributed.png convert -resize 48x48 -background white -alpha remove -colorspace Gray Octocat.png github_not_contributed.png
把图片放到相应的地方。然后写个脚本来更新这个指示器的状态,也就是获取数据之后再通过 awesome-client 调用update_github函数了。
#!/bin/bash -e
github_contributed () {
count=$(curl -sS "https://github.com/users/$USER/contributions" | grep -oP '(?<=data-count=")\d+' | tail -1)
[[ $count -gt 0 ]]
}
get_display () {
if [[ -n "$DISPLAY" ]]; then
return
fi
pid=$(pgrep -U$UID -x awesome)
if [[ -z "$pid" ]]; then
echo >&2 "awesome not running?"
exit 1
fi
display=$(tr '\0' '\n' < /proc/"$pid"/environ | grep -oP '(?<=^DISPLAY=).+')
if [[ -z "$display" ]]; then
echo >&2 "can't get DISPLAY of awesome (pid $pid)"
exit 2
fi
export DISPLAY=$display
}
get_display
if github_contributed; then
s='true'
else
s='false'
fi
echo "update_github($s)" | awesome-client
GitHub calender 目前是个 SVG 图片,位于https://github.com/users/用户名/contributions。
awesome-client 需要设置正确的DISPLAY环境变量才可以使用。这里使用pgrep取当前用户的 awesome 进程里的DISPLAY变量值。ps命令不太好用,不能同时指定多个条件。
万事俱备,只需要拿 cron 或者 systemd.timer 定时跑跑这个脚本就可以啦~
2015年3月14日更新:update_github脚本改用 Python 实现了,更好的错误处理(不会因为网络问题而认为今天没有贡献了),也改用当前日期而非 GitHub calender 的最后一个方块。更新后的脚本在 GitHub 上。
I want to be a Big Fish, but the lake is so small. I want to live in sea, but I have no way there. And they say, you aren't suitable for salty water.
To do it, or not to do it, it is wrong. This reminds me of my father.
I know about too many things, but none of them is good enough. 韩寒, I knew you were right, now I'm proof of your option.
It's so nice to meet you, CloudFlare. Really nice, not only your service, but your blog. You present me a larger world I'm looking forward to, a world I can only dream of, but fear that I will never reach. Even a piece of it.
There are 1724 days left. I've used more than a third now.
经过十二小时的旅程,转了五次车,又回到了这个熟悉的地方。因为年又来了。
依旧是简陋的陈设,依旧只有微弱的 3G 信号。可我还是回来了。所幸,今年除夕,据说是有规定,所以极近的地方并没有燃灯鞭炮,整夜只有远方并不觉得吵的连绵不断的噪音传来,正好和大雨声一样,屏蔽掉了夜里的杂音,让我第一次在除夕夜睡了个好觉。
春节一整天,却是阴沉沉的,因为外边在不间断地下着小雨。屋内灯光不甚明亮,在这种时候聊胜于无罢了。好在我有哆啦A梦的陪伴。也好在我把在北京都很少穿的毛衣带回来了。薄薄的,却抵得上小时候厚厚的两件。
回顾这一年。离开了那浑浑噩噩中选择的南京的初创公司。本来打算回家,再次为自己做一个负责的选择,却困于休息不好、压力山大,几个月过去了,尝试过几家公司,但没有成功。最后无奈之下,再次随意决定,重来到北京,继续自己的生活。
这家公司是在朝阳而不是海淀,不知道这到底算幸还是不幸。重访北京我最害怕的事情没有发生,可也发现,好多技术活动,我要花一个多小时的路程才能抵达。我是不独自坐出租车的,至少不能给差评的不会再坐了。而 Uber,它在向我要姓名,这使我很犹豫。
后来新的问题出现了。公司资金出了问题,拖欠了好几个月的工资。有段时间,我经常看到自己账户上还剩下多少银两,甚至想过罢工然后寻找新的工作。因为我很害怕很害怕。有些事情,人是永远不会想经历第二次的。我看过一部电影叫《时间规划局》(In Time)。在那个真正的「时间就是金钱」的世界中,当一个人的时间耗尽,生命也就终止了。来自社会底层的主人公意外获得了大量时间之后,飞奔着回家,要转给时间已所剩无几的母亲。他和他的母亲在路上看到了对方,飞奔着扑向对方,可是只晚了一秒钟,主人公拥抱在怀中的,已是时间归零的尸体。
还好,在我犹豫着要不要启动紧急计划的时候,工资终于到了一部分。警报解除,终于可以重新安心地生活了。
是的,属于自己的生活。不再是父母老师期望中的「好孩子」「好学生」,也不再是难得安宁地忍受网吧一样的环境,不再只是生存下去了。虽然依旧孤单,但灰色的画卷已经开始涂上的明亮的色彩。做自己喜欢的事情,做自己喜欢的自己,真好。这个世界没有我曾经历的那样充满恶意,也没有像我曾害怕的那样不能包容。虽然父母这边仍然是个麻烦。
事情在向好的方向发展。可是我依旧不知道是否还来得及,实现我那最初的梦想。上次是我自己不好,把事情搞砸了。花了很多时间去思考,去请教,去学习,可终究时间有限,大量的时间都花费在了计算机上。你们都说每一个人都值得获得那份幸福,希望对于除了编程和管理服务器之外什么都还不会的我依旧适用。
未来,我依旧有些许的迷茫和不确定。毕竟,这样的工作对于我来说太无趣了,而这样的队友也太难合作了。表达不清楚事情也就算了,我可以一点点慢慢确认;相关部分技术不懂也就算了,我可以引导你;可你丫的动不动闹情绪算个什么事!对不懂行的人有说有笑、对指出你的问题的人发脾气,能解决问题么?
本来想建立一个生活博客的,但是拖延症唉,新的一年里再努力吧!这一篇,就放在现在的博客上好了。
浓浓迷雾中,终于透出点点光亮。似乎还很远,但我知道,那是灯塔的方向。
通常,创建 git 提交使用的是 git add、git commit 这些高层命令。这些命令有个特点:它们都需要工作区的存在,并且很可能会改变工作区里的文件。
如果没有工作区,或者工作区不能用的时候怎么办呢?比如想在服务器上的纯(旧称:祼)版本库里的钩子脚本里创建提交,在版本库被更新时自动生成点东西什么的。一个简单的解决方案是再克隆一份,然后在那边弄好了再 push 过来。但那样的话,你得区分一次 push 是不是由你的脚本自身触发的了。这当然是可行的,但是,不觉得直接操作纯版本库更有意思吗 O(∩_∩)O~
或者,如果你的工作区里有一个文件叫「test」,另一个文件叫「Test」,而你当前能使用的文件系统和/或操作系统是不区分文件名大小写的,这样可能就没有办法通过工作区做想要的改动了。
我之前也曾用 pygit2 来直接创建提交。那个还是比较基础的,还是需要工作区。这次让我向大家介绍一下我的新玩法,深入 git 底层,围观一下一个提交的诞生历程~~(其实是早就玩过了的,只是一直没有分享出来而已 >_<
首先,克隆一个版本库来玩儿。直接在已有的版本库里玩太危险了,万一不小心玩坏了就囧了(虽然也不是多大的问题,毕竟我有备份的嘛=w=
git clone --bare ~/.vim dotvim
读者想要一起玩的话,可以从网络克隆我的 vim 配置版本库,如
git clone --bare git://github.com/lilydjwg/dotvim dotvim
进去 dotvim 目录里 ls 一下,可以看到,只剩下以前在 .git 目录里会见到的文件了呢:
>>> ls branches config description HEAD hooks index info objects packed-refs refs
要创建的提交是在 master 分支上。我们先使用 ls-tree 命令看看这个分支上有哪些文件。ls-tree 其实是列出 tree 对象用的,加上 -r 参数就会递归地把 tree 对象里的 tree 对象给列出来,就像 -R 之于 ls 命令一样。
不过你给它提交(commit)对象也可以的啦。它会自动取这个提交所指向的 tree 对象:
git ls-tree -r master
相当于
git ls-tree -r 'master^{tree}'
嗯,分支名实际上是指向这个分支上的最后一个对象的符号引用。
我要把 vimrc 文件里的注释行全删掉。要想修改一个文件,就得先找到要修改的文件,而不像添加文件那样直接加进去就可以了。让我们把要修改的 vimrc 文件的 hash 值找出来:
old_vimrc=$(git ls-tree -r master | awk '$4 == "vimrc" { print $3 }')
当然这里是不必用 -r 的啦。写在这里方便嘛,下一次想改 plugin 目录下的东西可以直接改路径就可以了,不用担心要改其它可能会忘记的东西。
然后拿 cat-file 命令看看这个 blob 对象。cat-file 命令我用得挺多的,因为经常会想看看另一个分支、或者另一个提交里某个文件长什么样子。
git cat-file -p $old_vimrc
其实这里可以直接指定要显示的对象的,比如master:vimrc就是 master 对应的提交上的 vimrc 文件。如果使用 zsh 的话,冒号后边的路径部分也是可以补全的哦。这里为了阐述原理,就做「分解动作」了。
得到了文件内容,就可以修改了。修改完毕,使用 hash-object 命令将文件存入 git 对象数据库里。这一句命令相当于修改好文件之后再做 git add 操作。hash-object 会返回对象的 hash 值。我们得把它记下来。
new_vimrc=$(git cat-file -p $old_vimrc | sed '/^"/d' | git hash-object -w --stdin --path vimrc)
不管之前有没有,先删一下 index,也就是所谓的「staging area」。已经添加但是还未提交的目录树就存在这个文件里边了。
rm -f index
然后,创建我们需要的 index。得使用 ls-tree 命令列出所有文件的信息,然后把我们修改过的信息加到末尾,会自动覆盖之前已有的项。如果删除这个列表里的某些项的话,就相当于是删除了那些文件。如果添加原本不存在的项,就是添加文件了。
{git ls-tree -r master; echo -e "100644 blob $new_vimrc\tvimrc";} | git update-index --add --index-info
index 已经准备好了。我们把目录树写到 git 对象数据库里吧:
new_master_tree=$(git write-tree)
我们得到了一个新的 tree 对象的 hash 值。当然因为目录树是树状的,以上命令实际上会写入多个 tree 对象。我们只要有根 tree 对象的 hash 值就可以了。
该创建提交对象了:
commit=$(git commit-tree -p master -m '在没有工作区的情况下创建的提交' $new_master_tree)
提交对象创建好还不够。那只是一个提交对象而已,我们还没有更新分支的信息呢。我们把这个提交作为新的 master 分支的头:
git update-ref refs/heads/master "$commit"
大功告成!
可以使用git show和git log看看成果了哦~
当然,如果想要钩子脚本里使用的话,记得在修改前加锁哦。
参考资料。
最近很火的 Rust 前不久发布了 alpha 版。正式版虽不说指日可待(还在各种大改中),但是也不是那么遥远了。而经过了这么久,再见 Rust,感觉完全不一样呢。
还记得第一次见 Rust,是在 Fantix 的博客上。现在只记得当时看到各种~和生命周期的东西,挺头疼的。而这次是看到 Rust for beginners 以及已经被合并到《The Rust Programming Language》这本书的官方 guide。感触很容易概括:「一门实用的类 Haskell 语言,是我很早就想要的东西呢。」于是才有了我的第一个 Rust 程序,以及后来的 各种语言实现的 swapview。
当然后来事实证明 Rust 不仅仅有着与 Haskell 类似的代数数据类型,比如有表示空的 unit 类型、表示可选的 option 类型、用于返回结果或错误的 Result 类型。作为一名曾经苦学 Haskell 还折腾过 OCaml 的人,看到这些熟悉的类型,感到甚是亲切。这种类型系统最大的特点是类型安全、没有 null 指针/类型。
我接触到的绝大多数编程语言,都会有 null 指针,或者 null / none / nil 类型:
都是一个不小心,没注意检查对象是不是 null 值就用,然后程序跑着跑着就出错了。
而 Haskell 和 Rust 都能有效地避免这一点,至少是你可以预先察觉,因为它返回的是不一样的类型。比如在 Rust 中,想要把字符串解析成整数,你写let a: i32 = "123".parse()不成。因为不是所有字符串都能解析成整数的,所以parse方法会返回一个Result<i32,ParseIntError>类型(早期版本是返回Option<i32>)。你需要显式地处理错误——或者忽略,如果你希望在出错的时候程序崩溃的话。不管选哪条路,写的时候都是明确知道这个地方可能出错的。不像我写 Python 时那样,直接想当然地写int(xxx),很少会想到想当然以为是个整数表示的xxx其实可能是别的什么东西(比如None)。我总不可能在每一次按.键(取属性)、(键(函数调用开始)、[键(取下标)时都先想想「相关对象会不会是奇怪的东西、是的话要怎么处理」吧?当然这样的错误处理会比较麻烦。如果一个项目不值得这样麻烦的错误处理的话,那就换个更适合的语言去做就是了。
Rust 另一个小特点是,if这类条件判断后边只能是布尔值,和 Haskell 一样,而和 Python、Lisp、Lua 等都不同,就更别说没有真正的布尔类型的 C 了。这样更严谨,挺好的,意义明确。像把0当成假值这种事 Lua 就不干,把空容器当假这事 Python 喜欢但是别的语言又不一样。早先版本的datetime模块甚至认为午夜是假的、其它时间才是真的……
Rust 还有个显著的特点是,关键字都特别短,但是不至于短到不认识,比如pub, fn, mut, ref, impl等。有些人不喜欢,我倒是觉得挺好的。非要写一长串字符浪费空间嘛,虽然现在的显示器不是终端机那样一行只能显示80字符,但我要分割成多列呢。笔记本显示器可以显示两列代码对照着看,外接显示器要显示两行三列还不计偶尔会用到的侧栏呢。
Rust 还继承了 Python 式的显式名称导入。只要不用星号,一个名字是从哪里来的,当前文件里搜一下就找到了。不像 Ruby 那样子,String 莫名其妙多了个方法不知道是干什么的?拿 Google 搜索整个互联网吧……
Rust 资源管理很有特点,我还没在其它语言里看到这种。Rust 程序里,编译器知道每一个对象的生命周期,所以可以在编译期就插入相应的释放资源的代码,不需要 gc 过一段时间停下所有工作来检查一遍。也不像引用计数那样得维护计数,引起很多不必要的内存写请求。毕竟 Rust 的目标是像 C++ 那样高效的系统级编程语言嘛。当然引用计数如果需要还是可以有的。最初 Rust 的另一目标——像 Erlang 那样的并发性,因为绿色用户级线程被官方移出之后就大打折扣了。不过因为类型检查和生命周期推断,线程安全的特性还是保留了下来。
Rust 有各式各样的 trait,类似于 Haskell 里的类型类。要指定资源释放时调用的函数的话,直接实现Drop trait 就可以了。比如我的:
struct AtDir { oldpwd: Path, } impl AtDir { fn new(dir: &str) -> io::IoResult<AtDir> { let oldpwd = try!(std::os::getcwd()); try!(std::os::change_dir(&Path::new(dir))); Ok(AtDir { oldpwd: oldpwd }) } } impl std::ops::Drop for AtDir { fn drop(&mut self) { std::os::change_dir(&self.oldpwd).unwrap(); } }
使用的时候直接在需要的作用域时生成一个变量就好,就像下边这样子。Rust 保证在其生命周期结束时调用drop方法。而且是按其所有者变量定义的顺序的逆序调用的。不像 Python,PEP 442折腾了之后,反而是把我一个模块的__del__方法在解释器关闭时的调用顺序弄错了。虽然 Rust 没有 Python 那样的with语句,但是拿Drop可以做到一样的效果,而且能保证调用的时机与预期的一致。
let _cwd = match AtDir::new(directory_name) { Ok(atdir) => atdir, Err(err) => return Err(err.desc.to_string()), };
Rust 编译器及标准库目前大部分(92.0%)使用 Rust 编写。而在此之前,Rust 竟然是使用 OCaml 编写的。这从侧面解释为什么目前 79.4% 使用 Go 编写 Go 语言用起来那么像 C(因为它的开发者用的是 C,设计目标好像也是更好的 C),而 Rust 虽然有很多借鉴自 C++ 的东西,导致其语法有些像 C,但写起来完全没有 C 和 Go 那样原始的感觉。这也是我更喜欢 Rust 的原因之一。
目前,除了还在改来改去,让我的程序过几天就各种报错编译不了之外,作为一名初学者,我能发现的另一个缺点就是编译极其费时了,特别是普通优化和链接时优化全开的时候,我一运行时间不到 0.2 秒的小程序,竟然需要半分钟才能编译好……
对了,之前给 Arch Linux 打包的 thestinger 不再打包 Rust 了,所以我开始在 archlinuxcn 源里维护64位的 rust-git、cargo-git(因为 Rust 更新的原因,至今还没打包成功……)以及 vim-rust-git。这些包是自动更新的,因此不出问题的话,有更新就会在一天内更新。
PS: 写的时候有点赶,希望没有写得太乱 ( >﹏<。)
使用了一段时间的 MySQL,体验与使用 PostgreSQL 完全不一样。使用 PostgreSQL 时,「it just works」,而 MySQL 则是「it just doesn't work out of box」。
MySQL 有个数据类型叫TIMESTAMP,顾名思义,就是时间戳,支持的时间范围是从UTC 1970年元旦凌晨零点到UTC 2038年元月19日三点14分零七秒。毫无疑问,这是个32位的 UNIX 时间戳。
那么你觉得,当 MySQL 在整数和这样的时间戳之间比较时,会发生什么呢?报错?还是把整数转成时间戳?或者把时间戳转成整数?都不是!MySQL 会首先把整数以十进制转成字符串,然后再把字符串转成时间。也就是,20141028000000这么大的整数,会转成字符串,然后按时间的格式理解,变成2014年10月28日凌晨零点。
直接把字符串转成时间没问题。可是,谁会把时间表达成如此奇怪的整数呢?
MySQL 有个叫BOOL的类型。可是,它的文档位于数的类型章节之中。而且,它仅仅只是TINYINT(1)的别名!这意味着,MySQL 中的布尔值与整数 0 和 1 是没有分别的。连 Python 都不如,至少 Python 的 bool 是 int 的子类。
于是乎,明明 SQLAlchemy 定义时写的是布尔类型,结果因为表结构是 SQLAlchemy 自动解析的,取出来就变成了整数。
CHECK
与上例类似。看起来,MySQL 是支持CHECK约束的。但是不能被表面现象蒙蔽了,文档后面写着「The CHECK clause is parsed but ignored by all storage engines」。只解析,假装自己支持,但是没有作用。这个问题在2007年二月有人报告了。近八年了,依旧如故。
utf8不是 UTF-8
MySQL 似乎从很早开始就支持一个叫utf8的编码了。可是,你往数据库里插入一个「😄」(😄)字符试试?你可以直接在本文后边评论试试。这个字符及其后的字符会消失,因为 MySQL 的utf8只支持 BMP(基本多文种平面)范围内的 Unicode 字符。也就是,MySQL 的utf8使用三字节表达,因此只支持 U+0000 到 U+ffff 范围内的字符。我曾经有篇文章就是因为插入了音调符号而被截断,现在只能小心地使用 HTML 转义形式来写了。
Arch Linux 的 AUR 也使用 MySQL,因此也遇到了字符神秘消失的事件。
如果使用的是 5.5 及以上的版本,可以使用一个 MySQL 称为utf8mb4的字符集,也就是用四字节表达的 UTF-8 编码。明明 UTF-8 是为了统一编码而诞生的,结果又被 MySQL 给分裂成了两个。
通常,软件会默认一个尽量普适的配置,让大多数人不需要折腾就用着很爽。MySQL 反其道而行之,binlog 默认使用STATEMENT。然后,一不小心使用了它不支持的查询就报错了,让人经过 Google 之后再手动给设置成MIXED格式。
MySQL 默认的事务隔离级别是repeatable read,看上去比 PostgreSQL 默认的read committed级别要高。但是呢,有一些很怪异的行为。
两个事务 A 和 B 开始了。A 读取数据库发现 id=1 的记录。B 把 id=1 的记录删除掉(并提交事务)。A 也决定把 id=1 的记录删除。然后 A 再读,咦?怎么 id=1 的记录还在??
PostgreSQL 在read committed级别下,删除也都能成功,但是删除之后是读不到数据了的。
PostgreSQL 在repeatable read级别下,后删除的那个事务会失败。
MySQL 在serializable级别下,后删除的那个事务才会失败。
并发更新时也是这样:
两个事务 A 和 B 同时执行update t set v = v + 1 where id = 2更新数据(假设原数据为 id=2, v=1),会和 PostgreSQL 的read committed级别一样,双方更新均成功。但是,当事务 B 提交之后,A 事务还是看到 v=1。在自己提交之前,自己的更新和其它已提交事务的更新都看不到。
我不知道 MySQL 这样的行为是否符合 SQL 标准。但我知道,它肯定不符合我的直觉:明明我都把数据给改了,为什么我自己都看不到呢?
2015年3月17日更新:安坚实的评论很赞!
MySQL 官方 C 库不支持异步,所以使用其的 Python 库完全没办法异步。
oursql 默认会处于自动提交模式,而且很久不更新了。
Oracle 自己弄的 MySQL Connector/Python 倒是没这个问题。但是有其它 N 个问题,比如你得重命名二进制数列的列名,不然会报错:
cursor.execute('select binary %s as a', (b'\xe0\xda\x94\xb8\x89\xf7',))
比如以下查询总是返回空,不管你的数据库里有什么:
cursor.execute('select * from users where token = %s', (bytes_object,))
比如 network.py:226 这里是这么写的:
packet = bytearray(4)
read = self.sock.recv_into(packet, 4)
if read != 4:
raise errors.InterfaceError(errno=2013)
于是,当你的返回结果很大,导致这里想接收的四字节数据不在同一次recv系统调用中时,就会抛出异常。真不知道写这库的人学过网络编程没,连 short read 都不知道处理。
至于像 PostgreSQL 的连接那样,通过with语句进行自动提交或者回滚就更别想了。
在 MySQL 的交互式命令行里,不小心写了一个反悔了的查询怎么办?比如回车后才发现输出太多了根本没意义,又或者查询里有个地方写错了。我下意识的反应是,按Ctrl-C,中止查询。在按下Ctrl-C的时候,如果查询还没结束,那么查询中止,一切安好。如果不小心慢了 0.01 秒,按键时查询已经执行完毕了呢?MySQL 命令行工具会直接退出(包括 MySQL 官方的,和 MariaDB 的版本),你只能再重新输入密码、重新连接。这是很神奇的事情。我试过了一些别的软件的成熟的交互式命令行工具,比如 bash、zsh、python、ghci、irb、erl,都不会在Ctrl-C时退出。lua、awesome-client 和 rusti 会退出,可前者只使用 ANSI C 的没办法,而后两者并不算成熟。
当然它有一个--sigint-ignore选项,如果你记得加上的话,Ctrl-C时就不会退出了,而是没有任何反应。它都不取消输入到一半的命令。
MySQL 的客户端库,在连接localhost时,或者不指定要连接的主机时,会连接到它默认的 socket 文件。
我有个 MySQL 实例在 3306 端口和默认 socket 文件上监听,另启动了一个实例用于一些测试性工作,监听在 3307 端口和自己指定的 socket 文件上。但是,当不指定-h 127.0.0.1时,即使指定了端口号-P 3307也无济于事。它依旧会连接默认的 socket 文件。我花了很长时间去调试我遇到的问题,直到在 htop 里按了一下l键,看到 MySQL 命令行工具连接的不是我设想的地址才恍然大悟。
指定连接不同的地方当然就应该连接到不同的地方,不然你告诉我我的指定没有生效也好啊。这点 PostgreSQL 就处理得更好。它也是默认连接 socket 文件,即使指定了端口号。但是,指定不同的端口号时它会去连不同的 socket 文件!对于 socket 文件来说,「端口号」其实是文件名后缀,比如/run/postgresql/.s.PGSQL.5433。这样子就不会不小心连错而不自知。(当然 PostgreSQL 也不会自作聪明地在你要连接localhost的时候给连接到 socket 文件上。)
tmux 我已经用了好几年了,然而从未使用得多么深入,偶尔有些小不满也一直没有去研究看看能不能解决,其中就包括这么一项:tmux 窗口名称(就是显示在状态栏上的那个)默认会随着前台所运行的命令的不同而自动变化。但是,如果窗口名称被设置过之后,不管是通过prefix A设置的,还是通过终端转义序列设置的,之后它就再也不会自动变化了。
本来这也不是多大的事。偶尔会因为不小心往终端输出了些二进制数据弄乱终端标题,我要么是把它重新设置成「zsh」,要么直接关掉再开一个窗口,反正是很容器的事情。可是呢,公司服务器的 zsh 会把终端标题设置成当前的工作目录,ssh 退出时也不会清除。本来呢,我是专门再开一个终端来跑,完事之后再关掉。可是,习惯的力量是巨大的,我还是会时不时地在 tmux 窗口里 ssh 连过去,然后 tmux 窗口名称就坏掉了。
今天我终于决定把此事查个水落石出。既然主动设置之后就不再变化,那么 tmux 肯定用某种方法把「主动设置过窗口名称」这个信息给记录了下来。然后我就去 tmux 源码里找啊找,结果很意外地看到一个叫「automatic-rename」选项!敢情 tmux 早知道有人会对此不爽,专门弄了个选项呀。然后直接在1500行的 man 文档里搜索这个选项名称就可以了。
默认,tmux 的「automatic-rename」选项的全局值为「on」,也就是根据正在前台运行的命令自动设置。一旦窗口获得了一个用户或者程序指定的标题,不管是创建窗口时指定的,还是后来通过「rename-window」改的,又或者是通过终端转义序列改的,窗口局部的「automatic-rename」值就会被设置为「off」,也就是不会再自动变化了。所以,想要恢复 tmux 窗口的这个行为,只要把这个选项再次打开即可:
tmux setw automatic-rename on
或者,取消设置此窗口的局部值,这样 tmux 会使用全局值:
tmux setw -u automatic-rename
终于又解决了一个困扰已久的小麻烦~话说,直接去源码里寻找,远比在比 wget 手册还要长的 manpage 里乱逛要高效呢=w=

| Theme: Aeros 2.0 by TheBuckmaker.com