一些天前,根据加州旅客的文章《kindle paperwhite越狱更换屏保》获得了自己的 Kindle Paperwhite 的 root 权限,就开始想着给它编译些东西了。恰巧小虾也在玩交叉编译,而且是 Python,于是自己也照着编译。
交叉编译 Zsh
交叉编译 Python 比编译 zsh 要难不少,所以,先简要说一下 zsh 等能够「无障碍交叉编译」的使用 Autotools 构建系统的软件是怎么编译的。
首先,弄清楚几个概念。「host」是指程序要运行的目标平台,「build」是指编译该程序的平台,而在编译编译器时会遇到的「target」则指的是其生成的文件所运行的平台。(参见CLFS 构建手册)
其次,得找个交叉编译器。有些发行版可能仓库里就有。但是 Arch 没有,所以我还是用的 zshaolin 的这个工具链。下回来解压了,把它的bin目录加到$PATH里。Zsh 里可以这么写:
path+=/path/to/arm-dyne-gcc_64bit-x-arm7a-21jan12/bin
然后就可以去 zsh 源码目录下开始编译啦。还是那三步,只是参数有些不一样而已:
mkdir build-arm && cd build-arm
../configure --host=arm-dyne-linux-gnueabi --enable-multibyte --enable-pcre --with-term-lib='ncursesw'
make
make DESTDIR=/kindle/software/zsh-5.0.2 install
且慢!我指定了--enable-pcre,却没有去检查自己是否有这个库。可能是 bug 吧,zsh 的 configure 脚本并没有检测到我其实没有 pcre 的 ARM 版库文件,于是它接着在很多检测过程中加入了-lpcre,导致检测结果与实际不符(比如它认为我的目标系统上没有setpgid()函数)。编译安装 pcre 到工具链的 sysroot 下后再次编译通过。
再编译一些需要的库
所以你看,使用 Autotools 构建系统的软件交叉编译起来挺容易的,加上需要的--host参数就好了。其它诸如 file、ncurses、readline 也是这么编译安装的。下边说说那些比较「个性」的软件的编译参数。它们基本上都必须在源码目录编译。
首先是 zlib:
CHOST=arm-dyne-linux-gnueabi ./configure
make && make DESTDIR=/kindle/software/zlib-1.2.8 install
TLS/SSL 很有用!OpenSSL:
CC=arm-dyne-linux-gnueabi-gcc LD=arm-dyne-linux-gnueabi-ld AR=arm-dyne-linux-gnueabi-ar RANLIB=arm-dyne-linux-gnueabi-ranlib ./Configure shared linux-armv4
make
make INSTALL_PREFIX=/ldata/media/temp/kindle/software/openssl-1.0.1e install_sw
注意最后不是make install哦,那个会安装一堆不需要的文档的。
对了,我好像忘记说了,以上软件make install之后的操作:
-
删除文档,比如
rm -rf share/man
-
复制到工具链的 sysroot 下,命令:
tar c . | tar xv -C /path/to/arm-dyne-gcc_64bit-x-arm7a-21jan12/arm-dyne-linux-gnueabi/sysroot
-
给二进制文件们减肥啦(以下命令需要 zsh;非 zsher 请自行使用合适的 find 命令代替):
arm-dyne-linux-gnueabi-strip **/*(*)
另外再附上 ncurses 的配置命令好了:
../configure --host=arm-dyne-linux-gnueabi --with-shared --with-normal --without-debug --without-ada --enable-widec --enable-pc-files --prefix=/usr/local
是的,我把软件都安装到/usr/local下了。在编译 Python 3.3 时的事实表明,这是给自己找麻烦……
编译 Python 啦
好了,准备工具完毕,我们来真正开始编译 Python 啦!
按照小虾的文章,首先修改Modules/Setup.dist文件,把需要的模块去掉注释。一定要把最后的xxsubtype给注释掉!因为它只是很无聊的示例模块……
除了要安装模块对应的程序库外(比如要 curses 模块就得先安装 ncurses 等),还要注意一点:如果开启 readline 支持的话,把它后边的-ltermcap删掉!
开始配置了:
mkdir build-arm && cd build-arm
echo ac_cv_file__dev_ptmx=yes > config.site
echo ac_cv_file__dev_ptc=no >> config.site
export CONFIG_SITE=config.site
../configure --host=arm-dyne-linux-gnueabi --build=arm --enable-shared --disable-ipv6
根据实际 ssh 过去的结果,我的 Kindle 有/dev/ptmx但是没有/dev/ptc,所以往config.site文件里写上那么两句。没办法,交叉编译时脚本不知道目标系统里是否有这两个设备文件。当然,你都设置成no也是没什么问题的。
--build=arm这系统纯粹是 Python 的这个配置脚本要求的,和之前所说的常见使用方法不一样的。IPv6 支持需要的某函数配置脚本找不到,那就禁用掉好了。
配置完成,开始 make?
根据所开启的模块支持不同,在编译过程中很有可能地,你会遇到Parser/pgen无法执行的问题。它被编译成 ARM 版了,当然无法执行了!解决方案是这样子的:
修改pyconfig.h中SIZEOF_LONG为正确值(比如 64 位 x86 下是8)。如果已经是对的就不要动了。然后重新生成个本地可运行的pgen:
rm Parser/*
make CC=gcc Parser/pgen
接着把pyconfig.h改回去。然后,为了避免pgen被重建,我们让 make 认为pyconfig.h没有被修改过:
touch -t 200001010000 pyconfig.h
继续编译!
如果又出来了架构不对的情况,删除刚刚编译pgen时编译出来的目标文件吧:
rm Parser/*.o
touch -t 210001010000 Parser/pgen
touch pgen 的原因是,不能让 make 又把它编译成本地不能运行的 ARM 架构的了。
架构不对的目标文件可能还有一些,按照错误提示删掉就好了。
最后,要生成 Python 的可执行文件啦!很可能地,你会遇到类似这个的错误(我自己这里的错误信息已经没啦,下边这个由加州旅客提供):
libpython3.3m.a(timemodule.o):在函数‘py_process_time’中:
/home/jiazhoulvke/Python-3.3.2/./Modules/timemodule.c:1076:对‘clock_gettime’未定义的引用
/home/jiazhoulvke/Python-3.3.2/./Modules/timemodule.c:1082:对‘clock_getres’未定义的引用
查阅clock_getres的 man 文档得知:
Link with -lrt (only for glibc versions before 2.17).
于是,复制 make 最后执行的那条链接命令,在后边加上lrt吧。如果crypt没有定义的话,还要加上-lcrypt。
终于可以安装啦
接下来,当然是把程序安装到 Kindle 上啦!首先执行个make DESTDIR=xxx install安装到某个目录,然后进去清理下吧:
arm-dyne-linux-gnueabi-strip **/*(*)
cd lib/python3.3
# 删除所有你不想要的模块,比如测试代码(`test`,不是`unitest`哦)、tk/idle,
# 还有 distutils 里一堆乱七八糟的东东
# 删除 Python 源码和 pyc 文件,我们只要 pyo 文件就好啦=w=
rm **/*.pyc?
# 在 zip 文件里 Python 可不认 __pycache__……
perl-rename 's=__pycache__/([^.]+).cpython-33.pyo$=\1.pyo=' **/*.pyo
rmdir **/*(/)
zip -9r ../python33.zip .
然后,把生成的python33.zip放到 Kindle 的/usr/local/lib目录下,Python 二进制文件也放到对应的位置。记住,库文件要使用 tar 而非 scp 来传输!像这样子:
tar c libz.so* | ssh kindle tar xv -C /usr/local/lib
其实不少库 Kindle 上已经有了,比如这里的 zlib。不过很奇怪,使用系统自带的 zlib 运行 Python 时会报如下警告:
python3: /usr/lib/libz.so.1: no version information available (required by /usr/local/lib/libpython3.3m.so.1.0)
另一个我发现无关紧要的警告是让你设置PYTHONHOME环境变量的:
Could not find platform independent libraries <prefix>
Could not find platform dependent libraries <exec_prefix>
Consider setting $PYTHONHOME to <prefix>[:<exec_prefix>]
其实不设置也是没关系的。
哦对了,现在我们的 Python 应该还跑不起来的吧!有可能缺少一点库文件的哦!把之前编译生成的对应的库文件全部拿tar扔到/usr/local/lib下吧。再说一遍,使用scp传输的话软链接会变成其指向的文件,浪费掉 Kindle 上宝贵的存储空间!
库文件扔进去之后,首先确认/etc/ld.so.conf里已经包含了/usr/local/lib,然后执行下ldconfig。
终于,我们的 Python 在 Kindle 上跑起来啦!
后记,及下载链接
这个是我编译的 Python 的文件大小:
-rwxr-xr-x 1 root root 5.4K Sep 15 00:15 /usr/local/bin/python3.3
-r-xr-xr-x 1 root root 4.0M Sep 15 00:15 /usr/local/lib/libpython3.3m.so.1.0
-rw-r–r– 1 root root 2.2M Sep 15 00:43 /usr/local/lib/python33.zip
主要支持特性有:SSL、readline、ncurese、zlib、中日编码集、Unicode 数据库等。最后再放百度网盘下载链接(包括好些东东哦)。
最后我要说一句,Kindle 才是真正的 Linux 啊!编译起来如此方便!还各种常见库(包括 glibc、zlib、OpenSSL、GTK 2)都有。想之前给 Android 编译点东西得砍掉多少特性啊!又有多少软件死活编译不成功 :-(
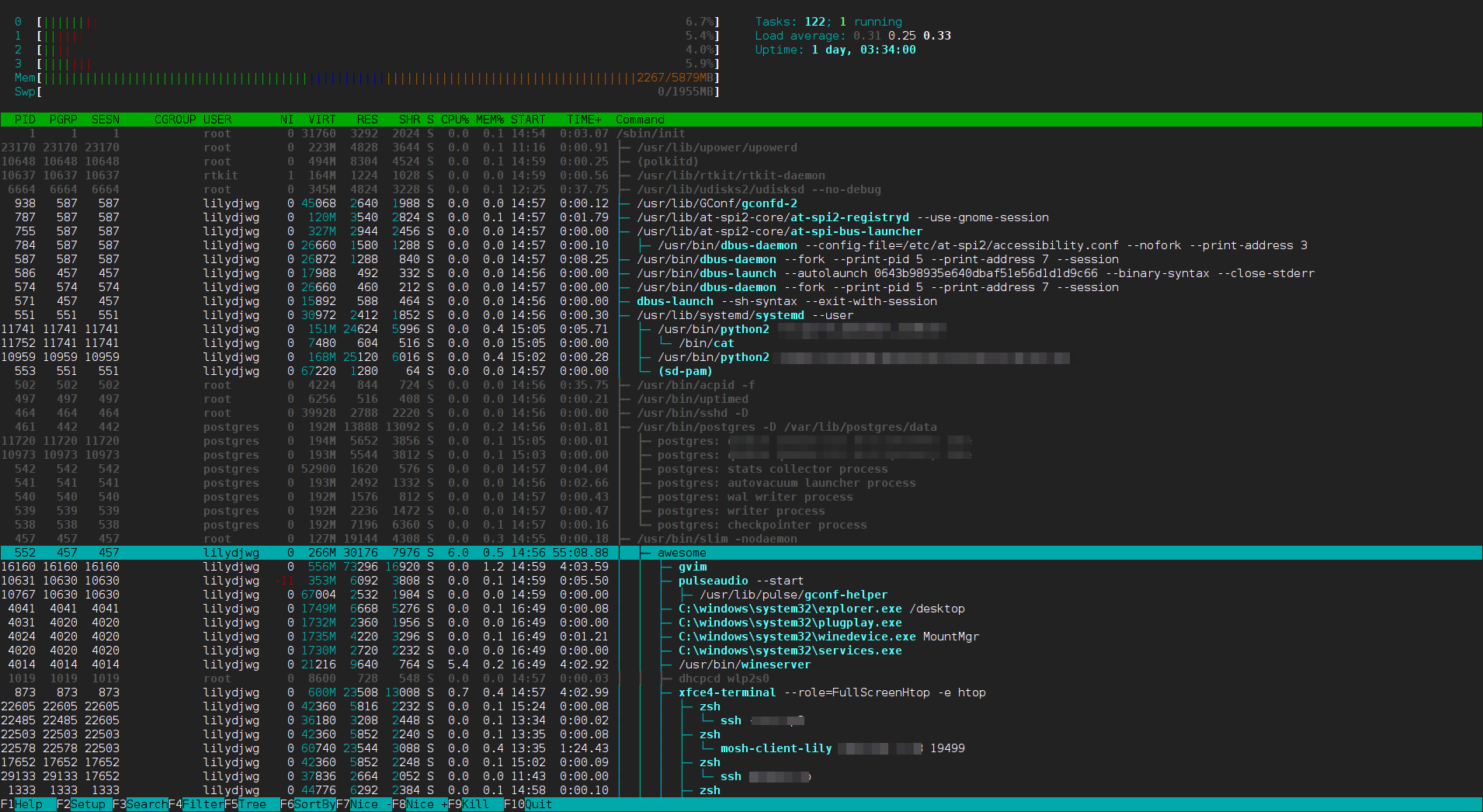
PS: Kindle 虽然也用 Java 的,但是它有 X Window,还有 GTK 2 以及 Awesome 窗口管理器哦~可惜它的 Awesome 没开启 D-Bus 支持。
更新:lxml
今天(2013年9月17日),成功编译了 Python 最著名的 XML 处理模块——lxml。编译方法是,指定CC环境变量,复制python3 setup.py build时出错的那两条编译命令并修改,编译出来目标文件存起来。将CC指定为自己的脚本来「生成」它想要的文件。链接时手动改命令链好就行。
因为有 .so 文件,lxml 不能打成 zip 包。因此我直接将*.pyc和*.pyo文件连同.so文件一同复制到 Kindle 的/usr/local/lib/python3.3/lxml下。由于版本不匹配,需要把libxml2.so.2.9.1文件也传到 Kindle 中去,覆盖了 Kindle 中旧版本的库文件,希望不会有问题。