序
swapview 起源于我很早之前看到的一个 shell 脚本。当时正在学习 Haskell,所以就拿 Haskell 给实现了一遍。为了对比,又拿 Python 给实现了一遍。而如今,我又在学习另一门新的语言——Rust,也拿 swapview 来练习了。相比仅仅输出字符串的「Hello World」程序,swapview 无疑更实际一些:
- 文件系统操作:包括列目录、读取文件内容
- 数据解析:包括简单的字符串处理和解析,还有格式化输出
- 数据处理:求和啊排序什么的
- 流程控制:循环啊判断啊分支什么的都有
- 错误处理:要忽略文件读取错误的
因此,swapview 成为了依云版的「Hello World」:-)
感谢所有给 swapview 提交代码的朋友们!
本文只是借 swapview 这个程序,一窥众编程语言的某些特征。很显然,编程语言们各有所长,在不同的任务下会有不同的表现。而且 swapview 各个版本出自不同的人之手,代码质量也会有所差异。
闪耀!那些令人眼前一亮的语言们
从运行效率上来看,C 如预期的一样是最快的。但令人惊讶的是,由我这个 Rust 初学者写的 Rust 程序竟然紧随其后,超越了 C++。
而原以为会跟在 Rust 之后的 C++,却输给了作为脚本语言存在的 Lua 语言的高效实现 LuaJIT(与 Rust 版本相当)。而且非 JIT 版本的 Lua 5.1 和 5.2 也都挺快的。Lua 这语言自带的功能非常少,语法也简单,但是效率确实高,让人又爱又恨的。
失望!那些没预期中的高效的语言们
没想到 Python 2 也挺快的,很接近 Go 了。PyPy 大概是因为启动比较慢的原因而排在了后面。Python 3 有使用两个版本的代码,Python3_bytes 把文件读取改为使用 bytes,仅在需要的时候才解码成 str。仅此之差,运行速度快了10%。可见 Python 的 Unicode 处理十分耗时,难怪 Python 3 在各种测试中都比 Python 2 要慢上一截。至于 PyPy3,怎么跑到那么靠后的地方去了呢……
Go 很快。至少比 Python 快。但也仅此而已了,不仅比 C++ 慢,甚至连 Lua(非 JIT 版)都不如。Go 语言版本虽然不是我写的,但我看过代码,感觉很原始。至少比 Lua 原始。看起来 Go 只不过是带接口和并发支持的 C 而已。而且,作为静态类型的编译型语言,却我却有一种很不放心的感觉。大约是因为我改动时发现传给 fmt.Printf 的参数类型和数目错了都不会得到警告或者错误的原因。而且我从来没见过 Go 编译时出现警告,对于还没入门的初学者写的、改过的程序,这样子不科学啊。早期我倒是见过 Go 报错了,但那只不过是编译器还不完善的表现而已。
传闻 NodeJS 很快。但至少它在 swapview 这种脚本中没能体现出来。正常版本比 Python 3 还要慢一点。而使用异步啊并行什么的版本还要慢上差不多三分之一,不知道怎么搞的。
编译型的 Chicken、OCaml、Haskell 都排在了一众脚本语言后边,虽然很可能是对语言本身不熟导致写出来的程序比较慢,但还是挺令人失望的。经过高手优化的 Haskell2 版本效率接近于 Python 3,但也到此为止了(因为不想使用 cabal 安装依赖,所以 Haskell2 没有参与这场对决)。我曾见过有人把 Haskell 代码优化到比 C 还快,但我宁愿去看汇编也不要去读那种代码……
Lisp 系(Chicken、Racket、SBCL(标注为 CommonLisp 的项)、Guile)也都挺慢的。不知道 LispWorks 之类的会不会快一大截呢。
预料之中的以及结果截图
Ruby 比 Python 略慢一点。
Java、Elixir 比较靠后。没办法,它们启动慢。也许以后我会出不考虑启动时间的版本。
以下是本文发表前的测试结果截图。其中 Erlang 版本因为有问题被信号所杀所以被扔在了最后。
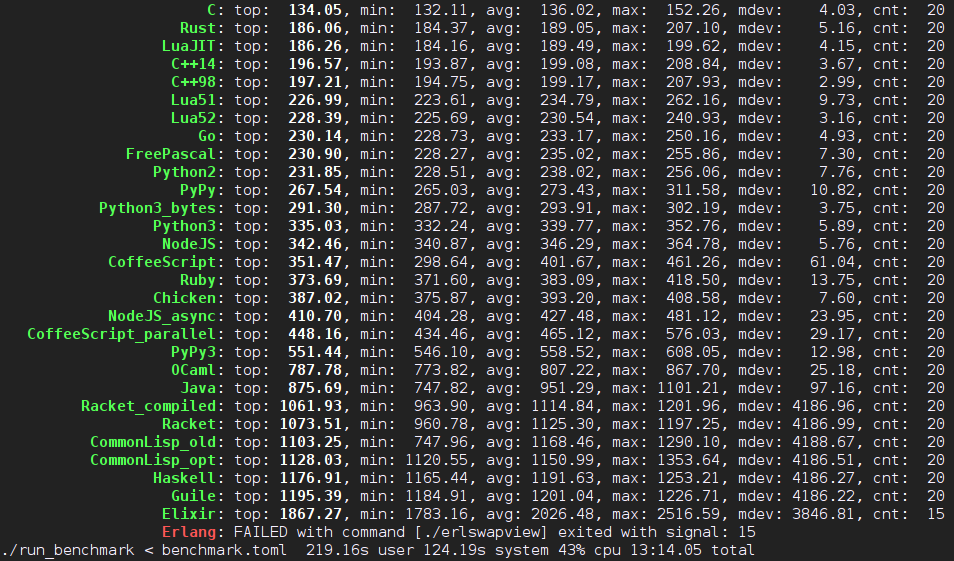
测试使用的是benchmark子目录中的 Rust 程序,使用cargo build --release命令即可构建。另外也可以使用 farseerfc 的 Python 脚本。
代码量
Elixir 代码量挺少的。Python、Ruby 也挺不错。Java 版本竟然跟 Haskell 一样。不管是 JavaScript 还是 CoffeeScript 都比较长,比 Java 还长。Rust 比 Python 长不少,但也比 Go 短不少。而 Go 比起 C、C++ 要短一些。最长的,除了我不了解的 Pascal,竟然还有因为程序出错还没有测试的 Erlang!如果不算按行读取的 line_server.erl 的放大,只有不到一百行,倒还不算多。
Elixir: 50
Julia: 51
Python3_bytes: 53
Python: 56
Ruby: 56
Racket: 58
Bash: 63
OCaml: 65
CommonLisp_old: 67
CommonLisp_opt: 67
Bash_parallel: 69
C++14_boost: 69
Guile: 70
Haskell: 73
Chicken: 75
Java: 75
NodeJS: 76
Vala: 78
Haskell2: 81
D: 86
Rust: 88
C++14: 89
CSharp: 91
Lua: 91
NodeJS_async: 93
CoffeeScript: 93
CoffeeScript_parallel: 95
PHP: 97
Rust_parallel: 98
Go: 103
C++11: 128
C++98: 141
C: 149
FreePascal: 185
Erlang: 232
编译速度
这个比较非常粗糙,比如联网下载依赖也被算进去了。不过可以肯定,不算下载依赖部分的话,Rust 是最慢的!其次是 Haskell。标榜编译速度非常快的 Go 并不是最快的,和 C++ 不相上下(当然不知道代码复杂之后会如何了)。
0.36 C 0.60 FreePascal 0.80 OCaml 0.83 CoffeeScript_parallel 1.48 CSharp 1.67 Vala 1.68 Erlang 2.13 NodeJS_async 2.27 C++14 2.49 Go 2.53 CoffeeScript 2.90 C++11 3.01 C++98 3.23 Java 3.52 Racket 3.98 NodeJS 6.05 CommonLisp_opt 7.07 D 9.01 C++14_boost 10.41 Haskell 13.07 Rust 14.74 Chicken 15.37 Rust_parallel
结语
这个项目最初只是练习而已。后来不同语言的版本有点多,于是才演变成众编程语言的竞技。也就随意地测试了一下在给定需求下不同语言的表现而已。其实比较有意思的部分,一是使用正在学习的编程语言写作程序的新奇感、新知、新的领悟(这也是我的测试程序使用 Rust 编写的原因),二是对比不同编程语言的风格和对同样需求的处理方式。
各位读者对 swapview 有任何补充和改进,欢迎贡献代码哦~项目地址:https://github.com/lilydjwg/swapview。
更新区
2015年1月9日更新:又收到了不少版本和改进,以下是最新的测试结果。很不幸地,现在已经跑得很快的 Erlang 在测试中又没反应被杀掉了。并行版的 Rust 的结果很不稳定,这次跑得好快!C++ 的除了 C++98 版的之外都到 Rust 前边去了。PHP 竟然比 LuaJIT 还要快!D 怎么到 PyPy 后边去了。
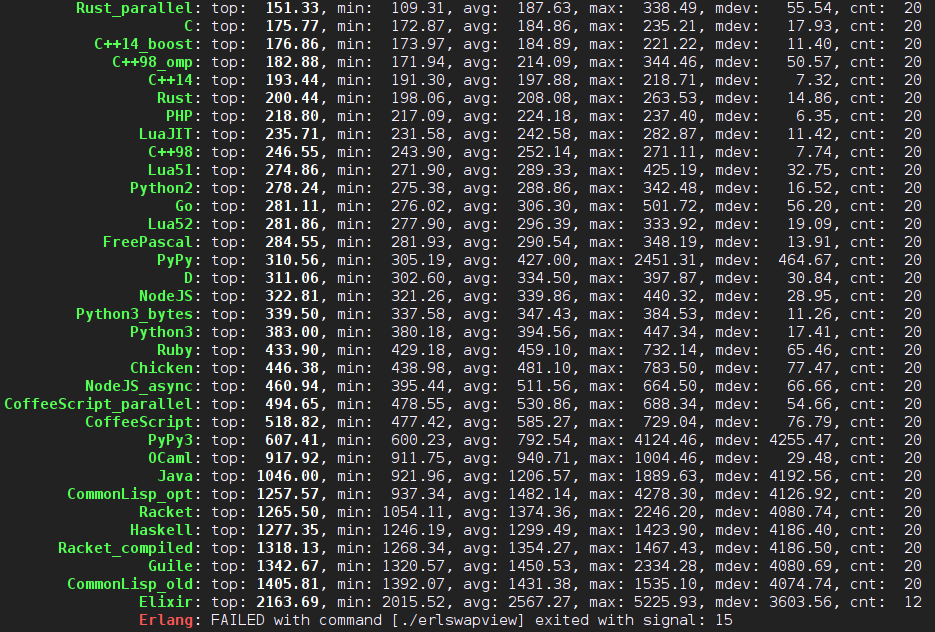
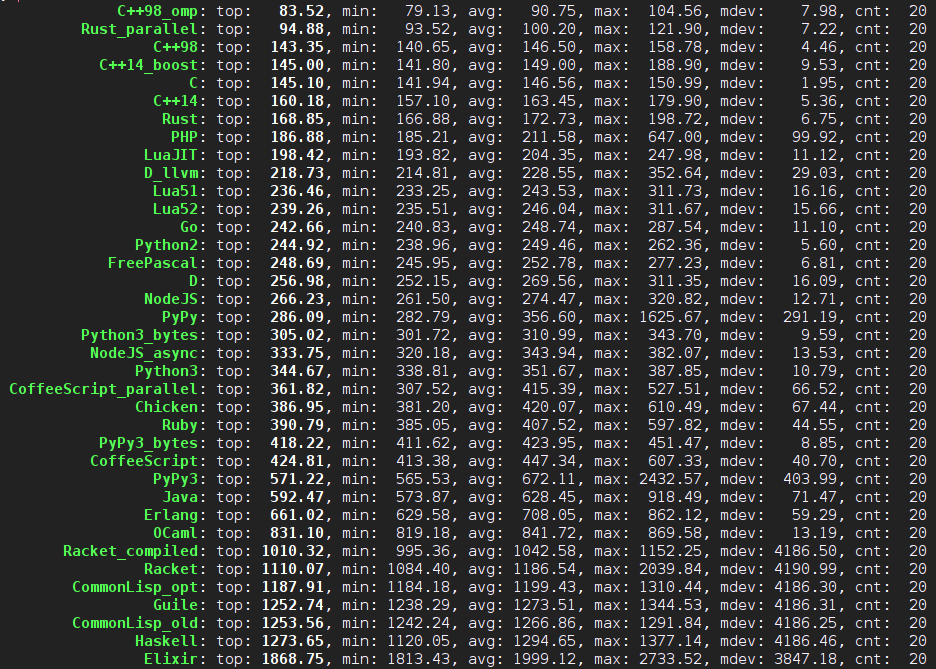
2015年1月10日更新:C++ 版本继续改进,好多都超越 C 了,Rust 1.0.0alpha 的并列版本又快又稳定,Erlang 版本终于跑完了全部测试而没有出事,LLVM 版 D 快了好多。
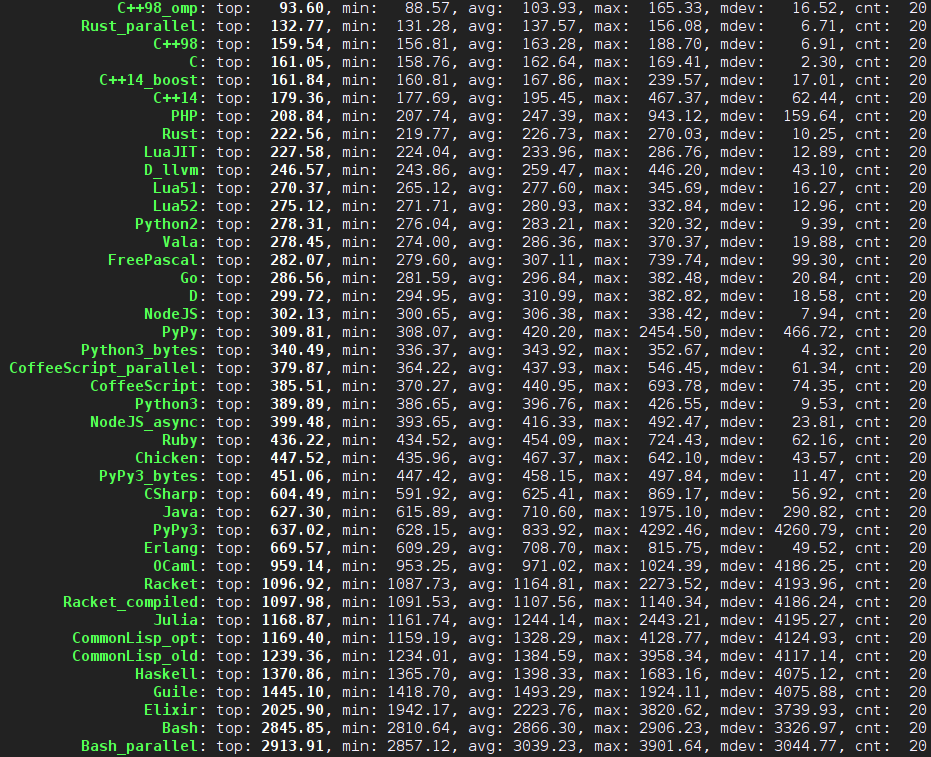
2015年1月18日更新:继续更新。又添加了若干语言,不过期待中的 Nim、Zimbu 以及传统脚本语言 Perl、Tcl 依旧缺席中。另外,正文也进行了更新,重新计算了代码量,添加了编译速度的粗略比较。

{kind=link}