上一篇《btrfs 翻车记》记叙了我们服务器上的 btrfs 出事的情况,好像吓到一些用户了 QAQ。其实那次情况比较特殊啦。一般来说,就算元数据用满了,也不至于改内核代码才能救回来。不过元数据满的问题确实困扰了许多用户,正好这些天群里有不少人遇到了,本文就记录一下元数据满了之后如何处置。
问题和处置
问题的现象是部分文件操作报错「No space left on device」,但是 df 等工具明明报告还有空间。btrfs filesystem usage 的输出是这样:
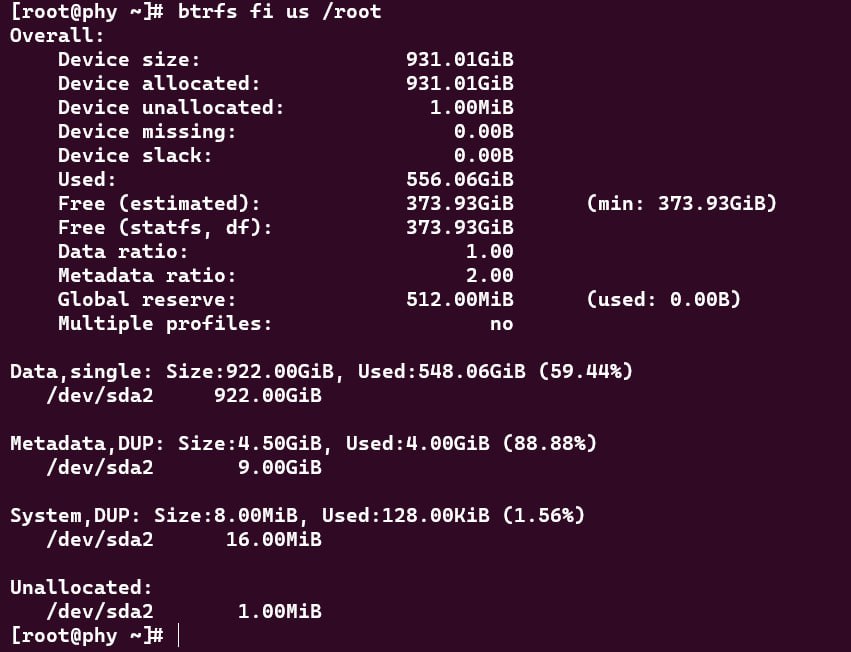
我们可以看到,还有 373G 的空闲空间(Free)呢。但是呢,「Device unallocated」已经不足 1G 了。在充分大的文件系统上,btrfs 会以 1G 为单位来分配块组(block group,简称 bg)。所以现在这个情况,已经无法分配新的 bg 啦。然后我们再往下看,「Metadata」的部分,总共 4.5G,已经用了 4G。还剩下 512M,刚好是 Global reserve 的大小。也就是说,不算保留空间的话,元数据已经没有空间可用了,所以才会报错。
那现在怎么办呢?如果文件系统上有不需要的很大的文件,并且没有快照,删除后空间可以立即释放的话,可以删除试试,看看能不能刚好空出来一个 bg。不然就试着跑一下 balance,像这样:
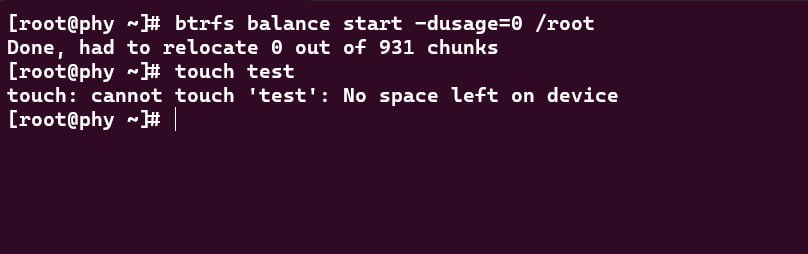
这个命令是说,把使用率为 0% 的数据 bg 整理一下。从输出「had to relocate 0 out of ...」可以看出,没有这样的 bg,操作没有效果。可以试试增加 -dusage 的值,看看能不能成功。很遗憾,这个案例中未能成功:

那只有另外添加一些空间来腾挪数据了。如果有闲置的分区(或者暂时用不上的 swap 分区)就可以拿来用。不然的话插个U盘也行。不需要多大,几个 G 就行。挪好数据就可以去掉了,不会长期使用的。另一种很有风险的做法是使用内存来暂存数据,但这样一旦死机或者断电,整个文件系统就完蛋了,不建议使用。
准备好空闲分区后,就可以 btrfs device add 添加上去了。这里通常要加 -f 参数,抹除分区里原有的数据。注意不要添加错设备了哦。
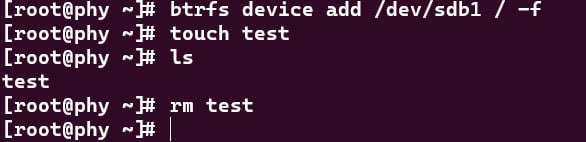
可以看到,设备添加上去之后,又可以往文件系统里写数据了。接下来跑 btrfs balance -dusage=10 之类的命令腾些数据 bg 出来就好了。这里要注意只 balance 数据 bg,不要动元数据的 bg,因为元数据越是集中存放,将来就越可能需要分配新的 bg,就越有可能遇到没 bg 可以分配的情况。
btrfs-heatmap 工具可以查看 bg 的分布和使用情况。以下是 balance 好之后的状态(使用 --curve linear 参数):

图中,白色的是数据 bg,蓝色的是元数据 bg。颜色越亮,使用率越高。纯黑的是未分配空间。可以看到,这里有大量用得不多的数据 bg。balance 操作就是把它们给合并了一些,空出来不少黑色区域(最下方的黑色部分是新添加的设备上的未分配空间)。这是 usage 截图:
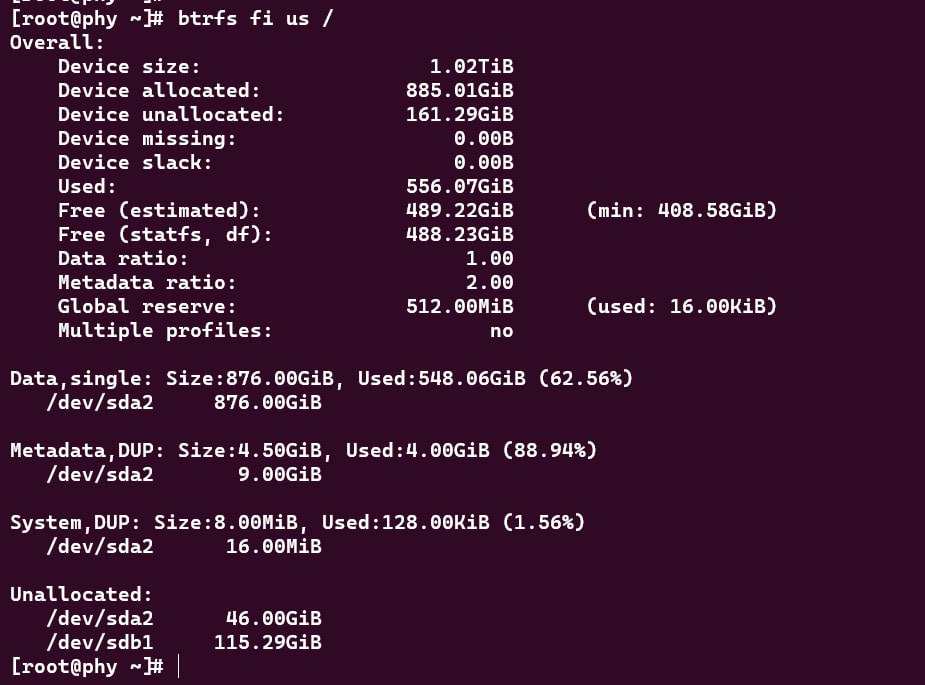
算一算,除去新添加设备的空间,原存储设备上也能有 46G 的未分配空间了(看上去新添加设备并没开始使用,只是让 btrfs 相信它有足够的空间用)。接下来把之前添加的设备删除就可以了:btrfs device del /dev/sdb1 /。等它运行完毕就可以拔掉该设备了(如果是可移动介质的话)。
预防
这个问题的本质就是 bg 的碎片化导致明明看上去有空间,但是元数据用不了,因此报错,需要手动处理。要识别即将出问题的文件系统也很简单:btrfs filesystem usage 看一看,如果「unallocated」很小(不足 1G)就要赶紧 balance 一下了(当然前提是有不少碎片化的空闲空间)。注意,这个时候千万不要删快照!删快照可能会快速消耗保留的元数据空间,从而导致添加设备都加不上、还报错只读的情况。
btrfs 最近添加了自动块组回收(automatic block group reclaim)功能,但默认并没有启用。因为是新功能,可能会有 bug,你也不知道它会什么时候运行,所以我暂时不建议使用。自己写个定时脚本,在系统空闲的时候运行也不错的。
本文中的图像素材均由遇到问题的群友提供。
