缘起
Linux 发行版的软件包管理器通常都会提供这么一个功能——查找文件在哪个仓库中存在的软件包里。实现起来也挺简单:仓库维护一个每个软件包里都有哪些文件的数据库,软件去查就可以了——假如用户不介意性能问题的话。
最开始,我使用的是 pkgfile。它是使用 C++ 编写的,会把 Arch 官方提供的 .files 数据库(压缩的 tar 归档)转成 cpio 归档再用(压缩可以靠 btrfs,问题倒是不大)。它比 pacman -F 可快多了,但是我后来不用了,因为它当时不支持多架构——即在 pacman.conf 里把 Architecture 设置为多个值,比如我用的 x86_64 x86_64_v3。现在等我写好了 pacfiles,才发现它终于在大半年之前支持多架构了……不过它看起来开发还是不太活跃,选项和输出格式也和 pacman -F 有很大的差别。
效果对比
最主要的功能是按文件名搜索,因此让我们先看看这个:
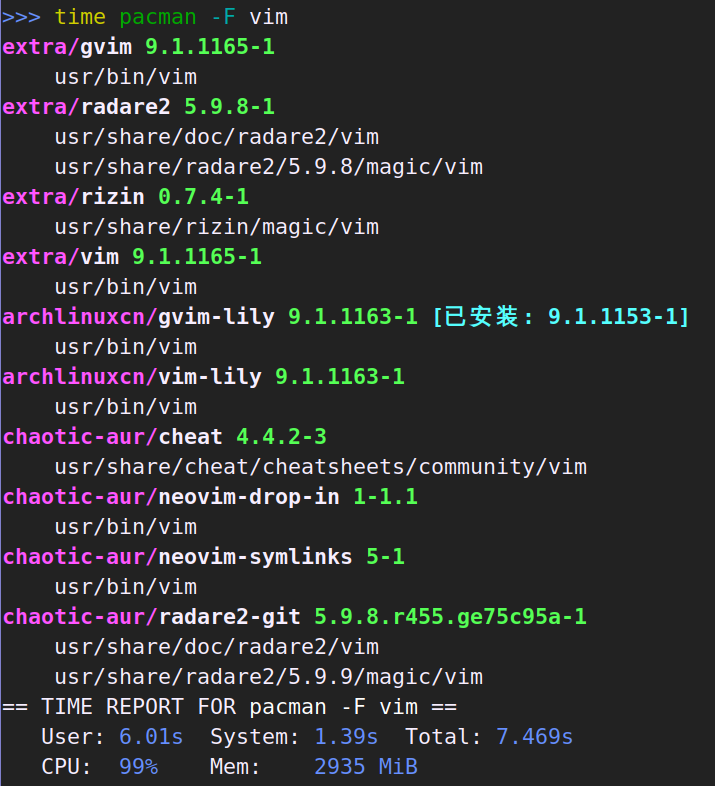
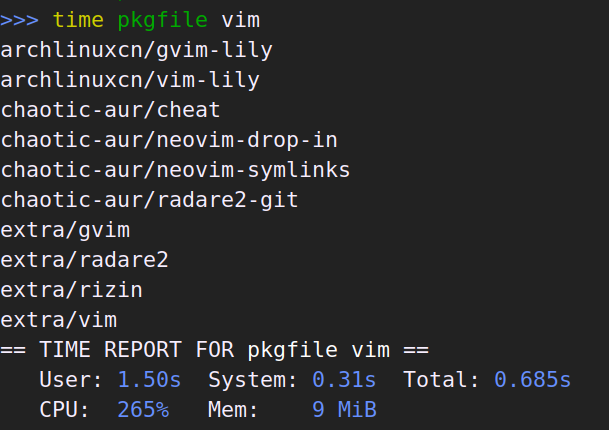
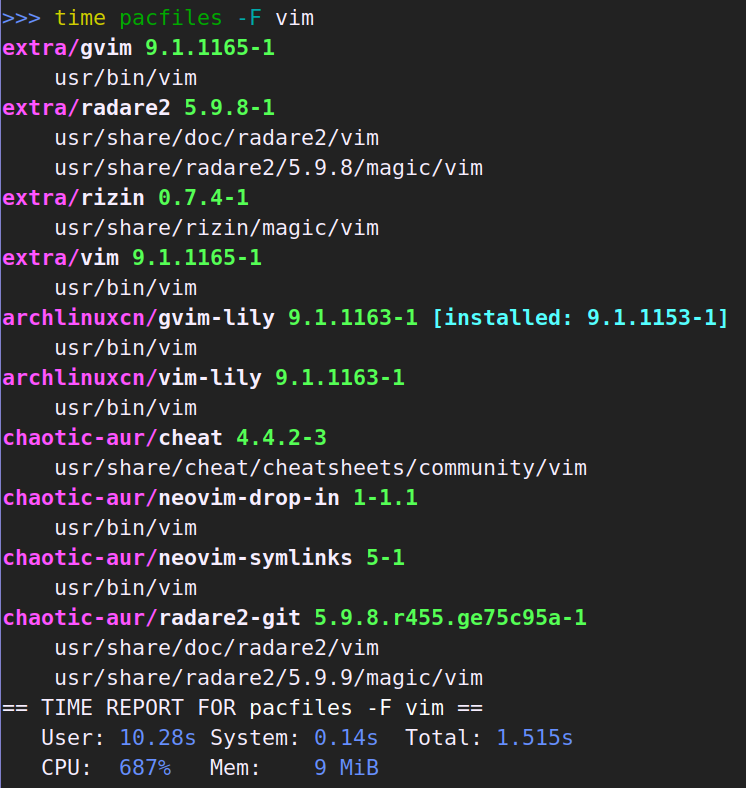
pacman -F 和 pkgfile 都是遍历整个数据库。pacman -F 和 pacfiles 是单线程的,pkgfile 是多线程,但我不知道为什么 pacman -F 会慢那么多。pkgfile 比 pacfiles 快一些,毕竟它提供的信息少、又不好看、还是多线程并行工作。另外值得注意的是,pacman -F 由于会预先加载整个数据库到内存,因此内存占用了近 3G。
有时候也会想要按完整路径搜索:
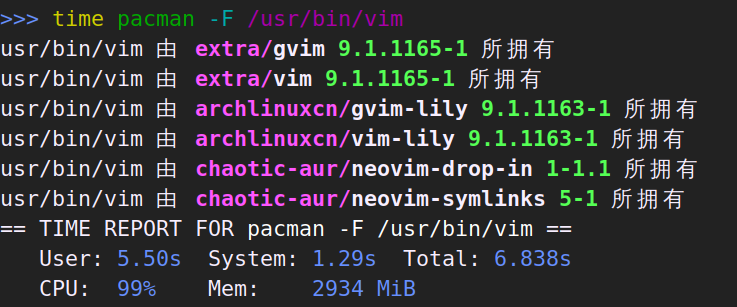
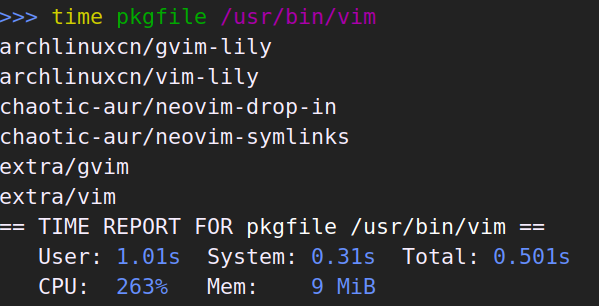
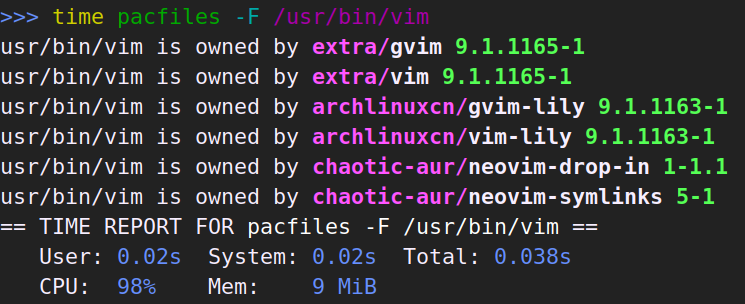
这次 pacfiles 因为有索引的帮助,并且不需要检查软件包是否已安装,比 pkgfile 快了不少。pacman -F 依旧又慢又吃内存。
接下来看看输出软件包的文件列表。这个由于输出结果多、输出格式又都差不多,我就重定向扔掉了,只看性能数据。



这次 pkgfile 比 pacfiles 略快。
有时候也会想用正则搜索:
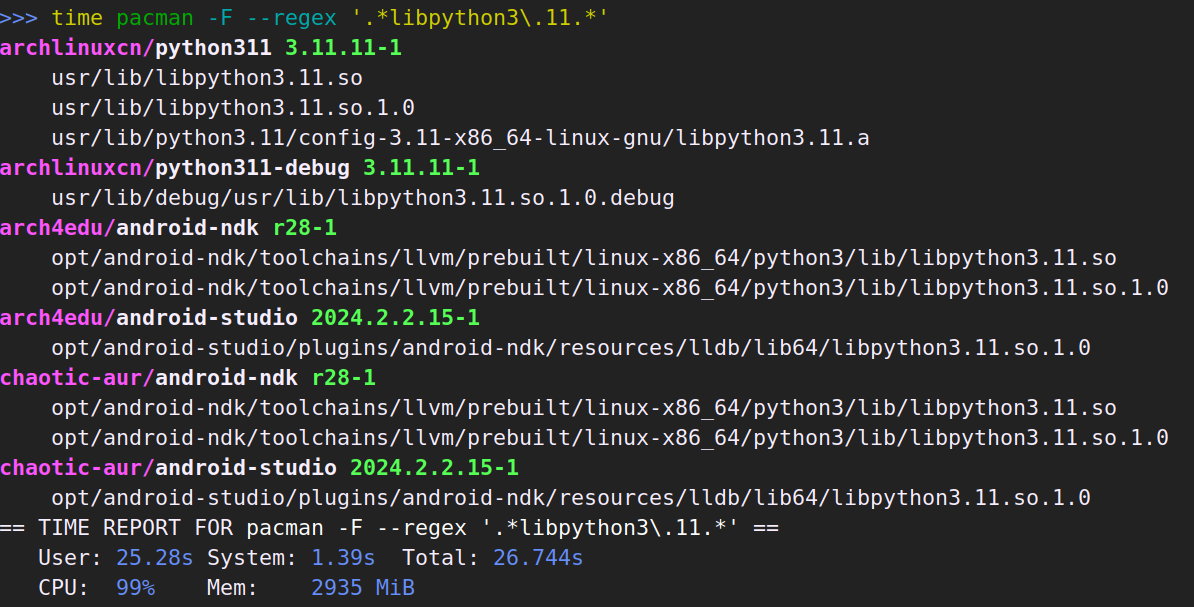
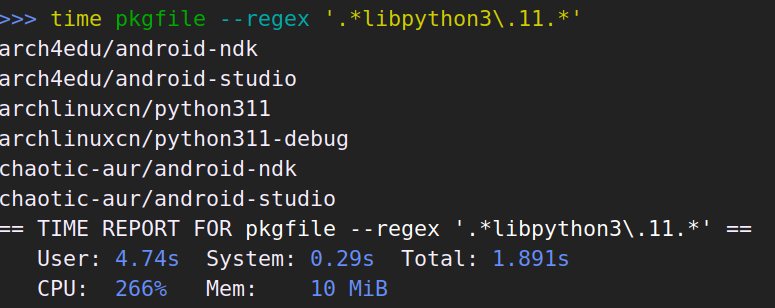
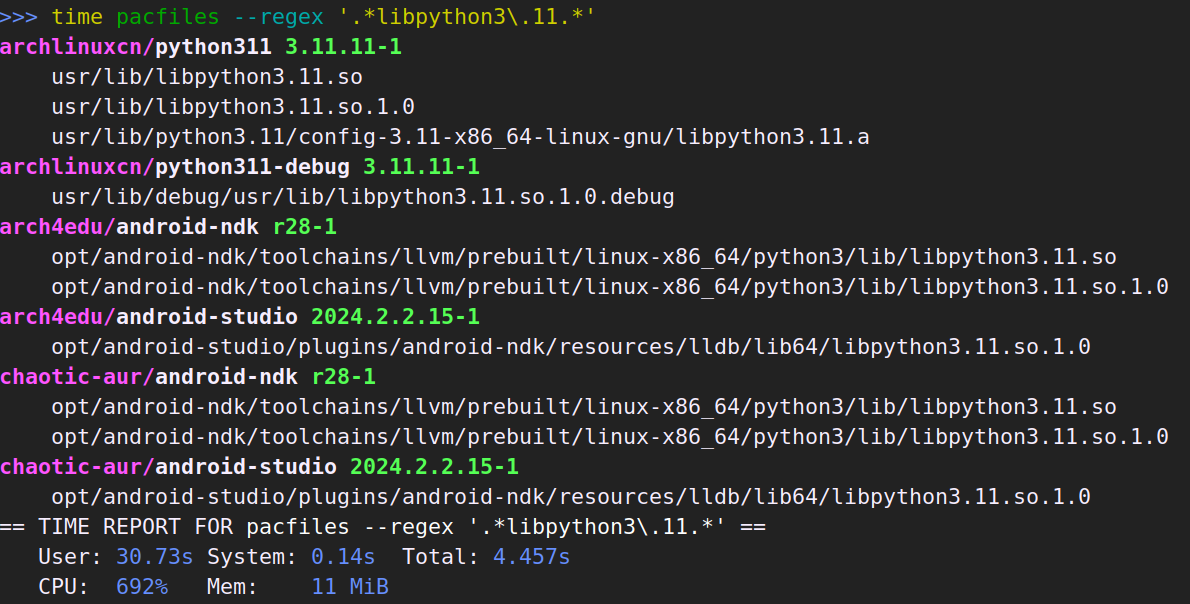
这次 pkgfile 比 pacfiles 快了不少。使用正则搜索时,pacfiles 没有使用索引,也是遍历数据,所以快不起来了。
不过 pacfiles 是支持通配符搜索的,也能用上索引,很快的。pacman -F 不支持这个。而 pkgfile 嘛……它不仅慢,好像还又出 bug 了。

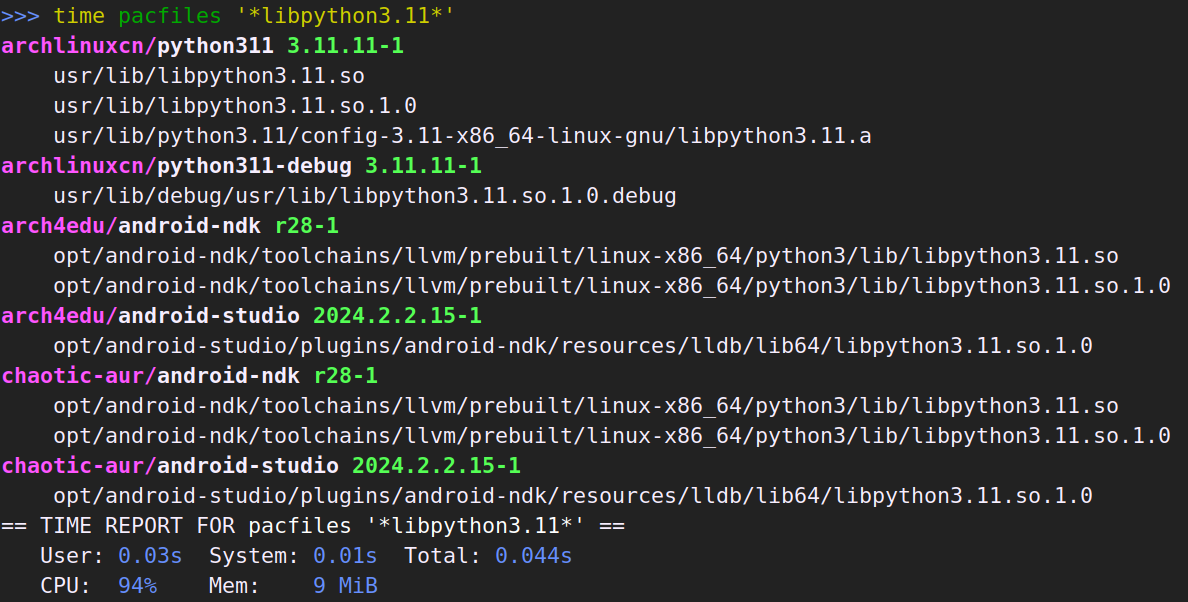
如果我写 pacfiles 之前得知 pkgfile 修了多架构那个 bug,我也许就不会写 pacfiles 了。不过现在对比下来,我也不后悔啦。
另外值得注意的是,pacfiles 无论是输出、还是命令行选项,都尽力兼容 pacman -F 的,以方便用户迁移。
幕后
其实我很早就想弄一个更快的 pacman -F 了。我首先想到的是,把数据塞进 SQLite3 里让它查。性能确实是好得不得了,但是一看生成的数据库,好几个 G……后来又尝试像 pacman -F 那样直接读压缩包,但是不一次性加载到内存,因此不需要那么多内存。但结果并不理想:解压和遍历搜索都不太能快得起来,最多并行处理多个数据库而已。plocate 是很快啦,但是它的数据结构是自己定制的,并不是库,不能直接拿来用。于是此事便放下了。
直到前不久,我读到《Succinct data structures》一文,特别是文中提到的 FM-index——这不正好能用来搜索文件名吗?不过,plocate 用的是什么数据结构来着?于是我去翻代码恢复了一下久远的记忆。哦,是 zstd 压缩的 trigram 倒排索引啊。好像也不错,还支持通配符呢。正则搜索它倒是没用上索引,因为作者认为「使用 locate 进行正则搜索太小众了」所以没有花精力去实现。
但是,以上关于数据结构的内容都不是重点!重点是,我发现了个 plocate-build 命令!它支持从纯文本创建 plocate 数据库!那我不是直接把文件名传给它就好了嘛~唯一有点遗憾的是,它不支持从管道读取文件名列表,因此需要先输出到临时文件中再给它使用,过程中会占用不少内存(/tmp 空间)。至于查询,调用 plocate 命令拿到结果再稍微处理一下就好了。于是想到就做,这就有了现在的 pacfiles(其实早期版本也在 git 历史里有)。
项目地址:https://github.com/lilydjwg/pacfiles。AUR 有 pacfiles-git 包。也可以 cargo install pacfiles 安装。
