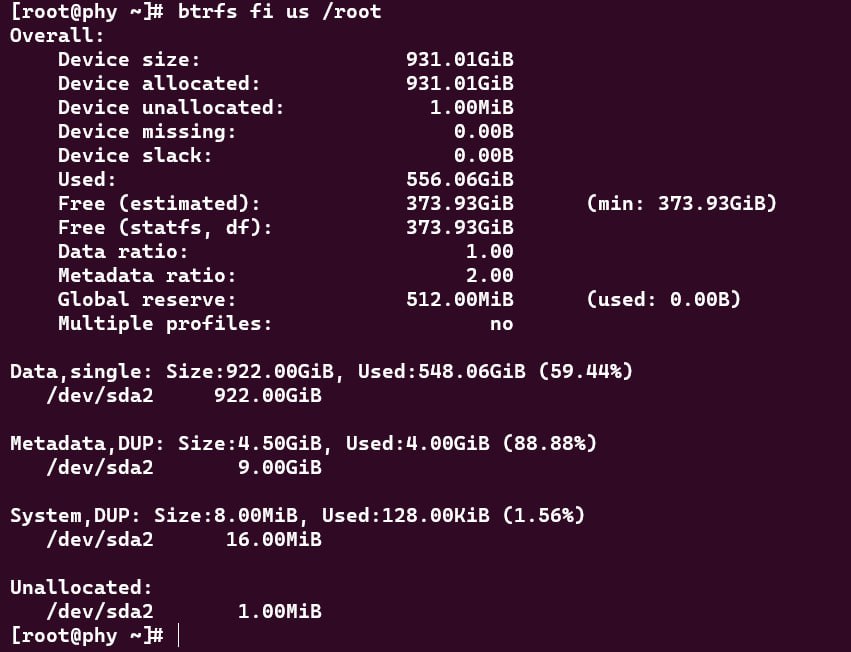
常见汉字字体
电脑系统要显示字,首先得有字体。现在 Linux 上常用的、在维护的开源中文字体就一套,同时被 Noto 和思源两个项目收录。Noto 系列字体是 Google 主导的,名字的含义是「没有豆腐」(no tofu),因为缺字时显示的方框或者方框被叫作「tofu」。思源系列字体是 Adobe 主导的。其中汉字部分被称为「思源黑体」和「思源宋体」,是由这两家公司共同开发的,两个字体系列的汉字部分是一样的。
Noto 字体在 Arch Linux 上位于以下软件包中:
-
noto-fonts: 大部分文字的常见样式,不包含汉字
-
noto-fonts-cjk: 汉字部分
-
noto-fonts-emoji: 彩色的表情符号字体
-
noto-fonts-extra: 提供额外的字重和宽度变种
Noto 系列字族名只支持英文,命名规则是 Noto + Sans 或 Serif + 文字名称。其中汉字部分叫 Noto Sans/Serif CJK SC/TC/HK/JP/KR,最后一个词是地区变种。
思源系列则有:
-
adobe-source-sans-fonts: 无衬线字体,不含汉字。字族名叫 Source Sans 3 和 Source Sans Pro,以及带字重的变体,加上 Source Sans 3 VF
-
adobe-source-serif-fonts: 衬线字体,不含汉字。字族名叫 Source Code Pro,以及带字重的变体
-
adobe-source-code-pro-fonts: 等宽字体,不含汉字。字族名叫 Source Code Pro,以及带字重的变体,加上 Source Code Variable。
-
adobe-source-han-{sans,serif,mono}-{cn,hk,jp,kr,tw}-fonts: 五个地区的汉字之黑体、宋体和等宽版本
-
adobe-source-han-{sans,serif,mono}-otc-fonts: 所有地区合体了的汉字之黑体、宋体和等宽版本
其中等宽版本的中文字体位于 [archlinuxcn] 仓库中。
思源汉字字体的字族名有两种,「独立包装」的版本(非 OTC 版本),是「Source Han Sans/Serif」或本地化名称、空格、地区代码(CN/HK/TW/JP/KR)。比如「思源黑体 CN」、「源ノ角ゴシック JP」等。也有带字重的别名。
而全部打包的 OTC 版本,字族名是本地化名称或者英文的「Source Han Sans/Serif」空格再加上「HC/TC/HC/K」变种代码。如果没有变种代码,则是日文变种。为了区分,香港繁体的版本附带「香港」字样,比如黑体叫「思源黑體 香港」。这些字体也有不同字重的别名。另外有个半宽的版本,是在字族名的变种代码前加「HW」字样,仅有少数几个字符是半宽的。
OTC 版本有趣的地方在于,对于大多数软件来说,不管你叫它的哪个地区的名字,它都会以设定的语种来显示。比如网页声明语种为日文(<html lang=ja>),那么不管字体指定为「源ノ角ゴシック」还是「思源黑体」或者「본고딕」,它都会「门上插刀、直字拐弯、天顶加盖、船顶漏雨」。所以用这个字体的话,不妨一律写「Source Han Sans」,然后加好语种标记。我知道的唯一例外是 mpv 的 ass 字幕文件,里边指定本地化名称的话,会使用那个语种的变体显示。
早些年还没有 Noto 和思源的时候,Linux 系统上通常使用文泉驿正黑或者文泉驿微米黑。后者是基于 Android 系统上的 Droid Sans Fallback 字体,体积较小。再之前是文鼎系列字体,也就是名字「AR PL」开头、包名叫 ttf-arphic-{uming,ukai} 的那些。
字体的属性
字体有很多属性,常用的有字族(family)、倾斜(slant)、字重(weight)。后两者合一起叫样式(style)。
字族就是它的名字啦。常见的指代字体的方式除了字族之外还有 Postscript 名,它不含空格、使用短横线将样式附加在名称之后,比如「DejaVuSans-BoldOblique」。后者是 CSS @font-face 规则中使用 local 时唯一指定样式的方法(除非该字体把样式也写到了字族名里)。
倾斜就是斜不斜,英文叫「Roman」「Italic」或者「Oblique」,Italic 是专门的斜体写法(更接近手写样式), Oblique 是把常规写法倾斜一下完事。
字重就更简单了,就是笔划的粗细。常见的有 Regular、Normal、Medium、Bold、Semibold、Black、Thin、Light、Extralight 等。
详细信息可以 man 5 fonts-conf 查询。
通用字族名
很多时候,程序并不在乎用户具体使用的是哪款字体,像很多网站的 CSS 那样把各个平台的常见字体全部列出来太傻了,又容易出问题。所以,人们发明了「通用字族名」,也就是 sans-serif (sans)、serif 和 monospace (mono) 这些。中文分别叫无衬线字体、衬线字体和等宽字体。但是中文字体不讲衬线不衬线的,而是叫「黑体」和「宋体」(有些地区叫「明体」)。黑体常用于屏幕显示的正文,而宋体常用于印刷文本的正文。
另外,中文没有斜体。英文使用斜体的场合,中文通常是使用仿宋或者楷体。中文本也没有粗体。传统上,强调的时候,中文使用着重号,也就是在字的下方或者右方加点,像这样子。
最近有一个新加的通用字族名叫作「emoji」。Pango 渲染表情符号的文本时,会自动使用 emoji 字体。但是 Qt 尚不支持,导致有时会出问题,而将 emoji 字体排到常规字体之前的做法,又会导致数字和空格显示为全角。火狐自带了一个 SVG 格式的 emoji 字体,会自动使用。很多软件(比如 Telegram)也会使用图片来取代 emoji 字符。
CSS 4 又加了一套 ui- 开头的字族名,但是除了 Safari 没浏览器支持。fontconfig 倒是可以通过配置来支持上,但是由于火狐的一个 bug 导致 ui-sans-serif 无效。
fontconfig 配置
大部分 Linux 桌面软件都或多或少地使用 fontconfig 来获取字体配置信息。其中 Pango(GTK 使用的文字渲染库)的支持是最好的。很多简陋的图形界面库则只用来读取默认字体,可能完全不支持字体回落,造成部分文字明明有字体却显示为「豆腐」。
了解了通用字族名,我们就可以为它们指定我们喜欢的字体啦。在 ~/.config/fontconfig/fonts.conf 里为每一个通用字族名像这样写即可:
<match target="pattern">
<test qual="any" name="family">
<string>sans-serif</string>
</test>
<edit name="family" mode="prepend" binding="strong">
<string>DejaVu Sans</string>
<string>文泉驿正黑</string>
<string>Twemoji</string>
<string>Font Awesome 6 Free</string>
<string>Font Awesome 6 Brands</string>
<string>Source Han Sans</string>
</edit>
</match>
因为我并没有完全采用思源字体来显示汉字,所以我还是为不同语言和地区变种分别匹配了不同的字体。我完整的配置文件见:https://github.com/lilydjwg/dotconfig/tree/master/fontconfig。其中,web-ui-fonts.conf 文件用于提供 CSS 4 新增的字族名,而 source-han-for-noto-cjk.conf 则使用思源系列字体来代替 Noto CJK 系列字体。
查看浏览器使用的字体
排查字体问题时,一个常见的要知道的事实是,软件究竟在用什么字体来显示这些文本?想知道这个通常很难,但是对浏览器来说却很简单。所以字体匹配问题首先看浏览器能不能复现。
火狐浏览器,对着有疑问的字点右键,选择「检查」(也可以按 Q 键),然后看弹出的开发者工具右边的「字体」选项卡即可。鼠标悬停到下方灰色的字体名上时还能将使用该字体的字高亮显示。
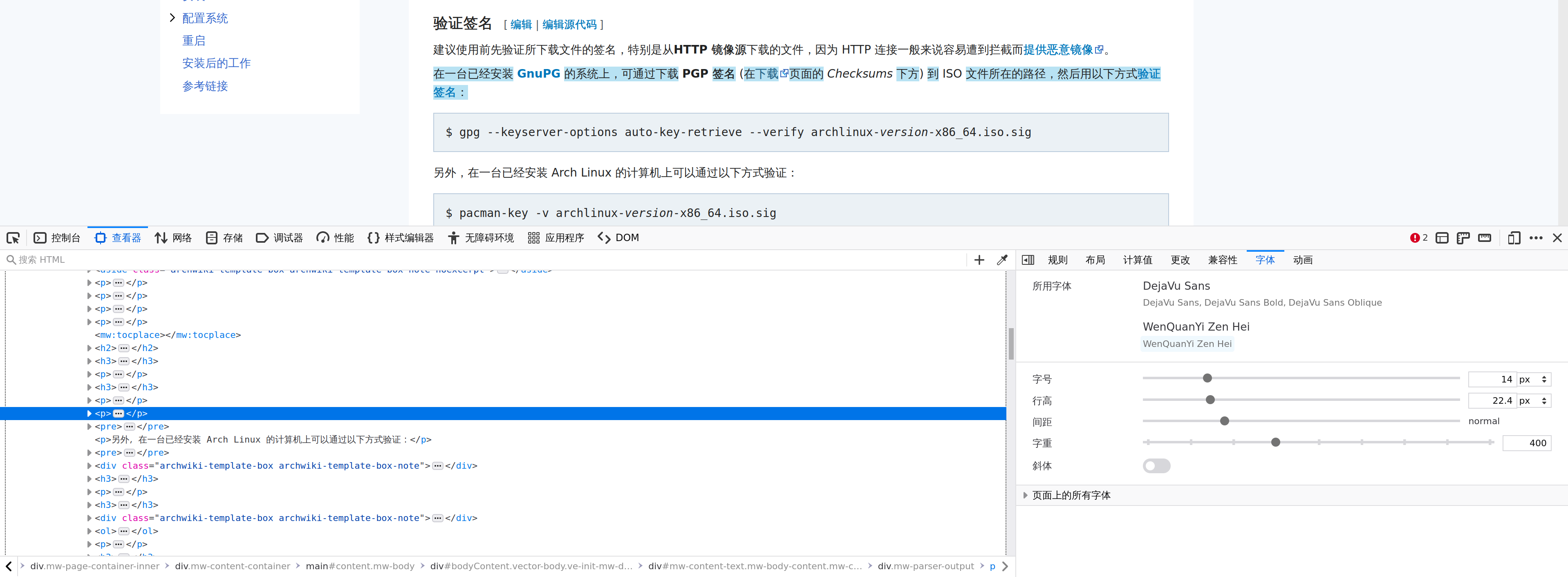
Google Chrome 浏览器及其变种类似,对着有疑问的字点右键,选择「检查」(也可以按 N 键),然后看弹出的开发者工具右边的「计算样式」选项卡,拖动到最下面,可以看到使用的字体名以及有多少个字形。
至于这个字体是怎么选上的,可以切换到「规则」(火狐)或者「样式」(Google Chrome)选项卡来看 CSS 规则。搜索「font-family」看看具体被应用上的规则是哪一条。通常这里会写上一大排字体名。火狐会将正在使用的那个加上下划线,但是有时候不准确(比如该 HTML 元素使用了多种字体)。更好的除错方法是,从头到尾一个个删字体,删到哪一个时网页上的字体变动了,就说明在使用的是哪一个。我通过这种方式找出了好些我学生时代不懂事从 Windows 下复制过来的字体导致的问题。
Google Chrome 默认的字体比较奇怪,是「Times New Roman」、「Arial」和「Monospace」。见《Google Chrome 中的字体设置》一文。
Qt
见 https://z.sh/qtfontbugs。其中最著名的 bug 是 QTBUG-80434 (https://z.sh/434)。
小技巧
使用 gucharmap 软件可以检查所有字符使用指定的字体时的渲染效果,以及它回落到什么字体上了。找到要查看的字符,然后对着它按住右键即可。
使用 fc-match -s NAME:charset=HHHH 可以查看针对指定字符的字体优先顺序,包含这个字符的字体会优先。如果不加 -s 就是看指定的模式会匹配上的字体了。其中 HHHH 是该字符的 Unicode 码点之十六进制值。如 fc-match :charset=7684 查看默认字体下「的」字会用什么字体,而 fc-match serif:charset=7684:lang=ja 查看在语种为日文的时候,使用 serif 字族名会使用哪个字体来显示「的」字。使用 fc-list :charset=HHHH 则是查看包含该字符的所有字体。
参考资料